Contents
- 1 概率论与数理统计-数理统计-方差分析与回归分析
- 1.1 单因素试验的方差分析
- 1.2 双因素试验的方差分析
- 1.3 一元线性回归
- 1.3.1 一元线性回归模型
- 1.3.2 \(a, b\) 的估计
- 1.3.3 \(\\sigma^{2}\) 的估计
- 1.3.4 线性假设的显著性检验
- 1.3.5 系数 \(b\) 的置信区间
- 1.3.6 回归函数 \(\\mu(x)=a+b x\) 函数值的点估计和置信区间
- 1.3.7 \(Y\) 的观察值的点预测和预测区间
- 1.3.8 可化为一元线性回归的例子
- 1.3.8.1 \(Y=\\alpha \\mathrm{e}^{\\beta x} \\cdot \\varepsilon, \\quad \\ln \\varepsilon \\sim N\\left(0, \\sigma^{2}\\right)\)
- 1.3.8.2 \(Y=\\alpha x^{\\beta} \\cdot \\varepsilon, \\quad \\ln \\varepsilon \\sim N\\left(0, \\sigma^{2}\\right)\)
- 1.3.8.3 \(Y=\\alpha+\\beta h(x)+\\varepsilon, \\quad \\varepsilon \\sim N\\left(0, \\sigma^{2}\\right)\)
- 1.4 多元线性回归
概率论与数理统计-数理统计-方差分析与回归分析
//TODO
参考:https://baike.baidu.com/item/%E5%9B%9E%E5%BD%92%E5%88%86%E6%9E%90 参考:概率论与数理统计.浙大第四版
方差分析和回归分析都是数理统计中具有广泛应用的内容. 本章对它们的 最基本部分作一介绍.
(本章节最好直接阅读教材,这里总结并不到位。这里引入了许多统计量的分布,证明参见:概率论与数理统计.浙大第四版)
单因素试验的方差分析
在科学试验和生产实践中,影响一事物的因素往往是很多的。 例如,在化工生产中,有原料成分、原料剂量、催化剂、反应温度、压力溶液浓度、反应时间、机器设备及操作人员的水平等因素每一因素的改变都有可能影响产品的数量和质量。 有些因素影响较大,有些较小。为了使生产过程得以稳定,保证优质、高产就有必要找出对产品质量有显著影响的那些因素.为此,我们需进行试验。 方差分析就是根据试验的结果进行分析,鉴别各个有关因素对试验结果影响的有效方法.
单因素试验
在试验中,我们将要考察的指标称为试验指标(对应随机变量)。影响试验指标的条件称为因素.(随机变量的参数,作为自变量看待) 因素可分为两类, 一类是人们可以控制的(可控因素); 一类是人们不能控制的(不可控因素)。例如,反应温度、原料剂量、溶液浓度等是可以控制的,而测量误差、气象条件等一般是难以控制的。以下我们所说的因素都是指可控因素。 因素所处的状态,称为该因素的水平(见下述各例)。 如果在一项试验的过程中只有一个因素在改变称为单因素试验,如果多于一个因素在改变称为多因素试验。
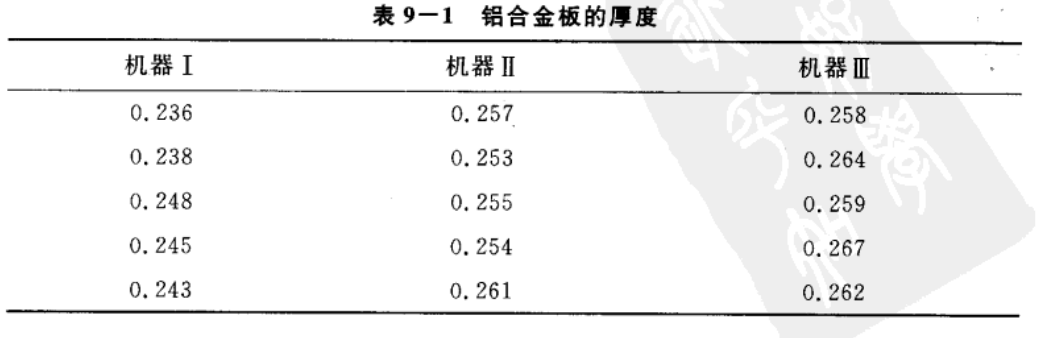
例子 设有三台机器,用来生产规格相同的铝合金薄板. 取样,测量薄板的 厚度精确至千分之一厘米.得结果:
这里,试验的指标是薄板的厚度。机器为因素,不同的三台机器就是这个因素的三个不同的水平。 我们假定除机器这一因素外,材料的规格、操作人员的水平等其他条件都相同。这是单因素试验。 试验的目的是为了考察各台机器所生产的薄板的厚度有无显著的差异,即考察机器这一因素对厚度有无显著的影响。 如果厚度有显著差异,就表明机器这一因素对厚度的影响是显著的
本节仅限于讨论单因素试验.
方差分析法
在实际中试验的指标往往要受到一种或多种因素的影响。方差分析就是通过对试验数据进行分析,检验方差相同的多个(多于两个)正态总体的均值是否相等,用以判断各因素对试验指标的影响是否显著。方差分析按影响试验指标的因素的个数分为单因素方差分析、双因素方差分析和多因素方差分析,本章只介绍前面两种。
在上面例子中,我们在因素的每一个水平下进行独立试验,其结果是一个样本. 表中数据可看成来自三个不同总体(每个水平对应一个总体)的样本值. 将各个总体的均值依次记为 \(\\mu\_{1}, \\mu\_{2}, \\mu\_{3}\). 上面的例子的问题是:机器这一因素对厚度的影响是显著?按题意需检验假设: \(H\_{0}: \\mu\_{1}=\\mu\_{2}=\\mu\_{3}\) \(H\_{1}: \\mu\_{1}, \\mu\_{2}, \\mu\_{3}\) 不全相等.
现在进而假设各总体均为正态变量,且各总体的方差相等,但参数均未知. 那么 这是一个检验同方差的多个正态总体均值是否相等的问题.
下面所要讨论的方差分析法,就是解决这类问题(检验同方差的多个正态总体均值是否相等)的一种统计方法.
单因素试验方差分析的数学模型与假设检验问题
现在开始讨论单因素试验的方差分析. 设因素 \(A\) 有 \(s\) 个水平 \(A\_{1}, A\_{2}, \\cdots, A\_{s},\) 在水平 \(A\_{j}(j=1,2, \\cdots, s)\) 下,进行 \(n\_{j}\\left(n\_{j} \\geqslant 2\\right)\) 次独立试验,得到如下图表的结果: 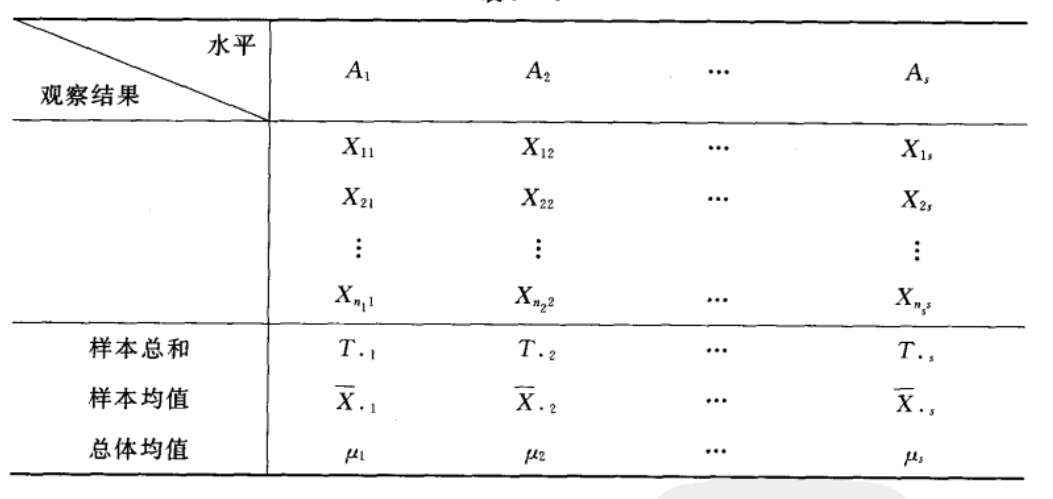
我们假定 : 各个水平 \(A\_{j}(j=1,2, \\cdots, s)\) 下的样本 \(X\_{1 j}, X\_{2 j}, \\cdots, X\_{n\_{j} j}\) 来自具有相同方差 \(\\sigma^{2},\) 均值分别为 \(\\mu\_{j}(j=1,2, \\cdots, s)\) 的正态总体 \(N\\left(\\mu\_{j}, \\sigma^{2}\\right), \\mu\_{j}\) 与 \(\\sigma^{2}\) 未知. 且设不同水平 \(A\_{j}\) 下的样本之间相互独立.
由于 \(X\_{i j} \\sim N\\left(\\mu\_{j}, \\sigma^{2}\\right),\) 即有 \(X\_{i j}-\\mu\_{j} \\sim N\\left(0, \\sigma^{2}\\right),\) 故 \(X\_{i j}-\\mu\_{j}\) 可看成是随机误差. 记 \(X\_{i j}-\\mu\_{j}=\\varepsilon\_{i j},\) 则 \(X\_{i j}\) 可写成: \(\\left.\\begin{array}{l}X\_{i j}=\\mu\_{j}+\\varepsilon\_{i j} \\ \\varepsilon\_{i j} \\sim N\\left(0, \\sigma^{2}\\right), \\text { 各 } \\varepsilon\_{i j} \\text { 独立 }, \\ i=1,2, \\cdots, n\_{j}, j=1,2, \\cdots, s,\\end{array}\\right}\), 其中 \(\\mu\_{j}\) 与 \(\\sigma^{2}\) 均为未知参数. 上式称为单因素试验方差分析的数学模型. 这是本节的研究对象.
方差分析的任务是对于以上模型: 1)检验 \(s\) 个总体 \(N\\left(\\mu\_{1}, \\sigma^{2}\\right), \\cdots, N\\left(\\mu\_{s}, \\sigma^{2}\\right)\) 的均值是否相等,即检验假设: \(H\_{0}: \\mu\_{1}=\\mu\_{2}=\\cdots=\\mu\_{s}\) \(H\_{1}: \\mu\_{1}, \\mu\_{2}, \\cdots, \\mu\_{s}\) 不全相等. 2)作出未知参数 \(\\mu\_{1}, \\mu\_{2}, \\cdots, \\mu\_{s}, \\sigma^{2}\) 的估计.
一些记号: 为了更好地讨论以上方差分析,我们将 \(\\mu\_{1}, \\mu\_{2}, \\cdots, \\mu\_{s}\) 的加权平均值\(\\frac{1}{n} \\sum\_{j=1}^{s} n\_{j} \\mu\_{j}\) 记为 \(\\mu,\) 即\(\\mu=\\frac{1}{n} \\sum\_{j=1}^{s} n\_{j} \\mu\_{j}\),其中 \(n=\\sum\_{j=1}^{s} n\_{j}, \\mu\) 称为总平均. 再引入\(\\delta\_{j}=\\mu\_{j}-\\mu, \\quad j=1,2, \\cdots, s\),此时有 \(n\_{1} \\delta\_{1}+n\_{2} \\delta\_{2}+\\cdots+n\_{s} \\delta\_{s}=0, \\delta\_{j}\) 表示水平 \(A\_{j}\) 下的总体平均值与总平均的差异,习惯上将 \(\\delta\_{j}\) 称为水平 \(A\_{j}\) 的效应.
有了上面的记号,单因素试验方差分析的数学模型可以改写成如下形式: \(\\left.\\begin{array}{l}X\_{i j}=\\mu+\\delta\_{j}+\\varepsilon\_{i j} \\ \\varepsilon\_{i j} \\sim N\\left(0, \\sigma^{2}\\right), \\text { 各 } \\varepsilon\_{i j} \\text { 独立 } \\ i=1,2, \\cdots, n\_{j}, j=1,2, \\cdots, s \\ \\sum\_{j=1}^{s} n\_{j} \\delta\_{j}=0\\end{array}\\right}\)
有了上面的记号,假设检验问题也可以描述成如下形式: \(H\_{0}: \\delta\_{1}=\\delta\_{2}=\\cdots=\\delta\_{s}=0\) \(H\_{1}: \\delta\_{1}, \\delta\_{2}, \\cdots, \\delta\_s\\text {, 不全为零 } .\)
平方和的分解
下面我们从平方和的分解着手,导出假设上面检验问题的检验统计量.
引入总偏差平方和:\(S\_{T}=\\sum\_{j=1}^{s} \\sum\_{i=1}^{n\_{j}}\\left(X\_{i j}-\\bar{X}\\right)^{2}\), 其中\(\\bar{X}=\\frac{1}{n} \\sum\_{j=1}^{s} \\sum\_{i=1}^{n\_{j}} X\_{i j}\)是数据的总平均. \(\\mathrm{S}_{\\mathrm{T}}\) 能反映全部试验数据之间的差异,因此 \(S_{T}\) 又称为总变差.
记水平 \(A\_{j}\) 下的样本平均值为 \(\\bar{X}_{\\cdot j},\) 即\(\\bar{X}_{\\cdot j}=\\frac{1}{n\_{j}} \\sum\_{i=1}^{n\_{j}} X\_{i j}\)
则可以改写总偏差平方和\(S\_{T}\): \(\\begin{aligned} S\_{T} \&=\\sum\_{j=1}^{s} \\sum\_{i=1}^{n\_{j}}\\left\[\\left(X\_{i j}-\\bar{X}_{\\cdot j}\\right)+\\left(\\bar{X}_{\\cdot j}-\\bar{X}\\right)\\right\]^{2} \\ \&=\\sum\_{j=1}^{s} \\sum\_{i=1}^{n\_{j}}\\left(X\_{i j}-\\bar{X}_{\\cdot j}\\right)^{2}+\\sum_{j=1}^{s} \\sum\_{i=1}^{n\_{j}}\\left(\\bar{X}_{\\cdot j}-\\bar{X}\\right)^{2}+2 \\sum_{j=1}^{s} \\sum\_{i=1}^{n\_{j}}\\left(X\_{i j}-\\bar{X}_{\\cdot j}\\right)\\left(\\bar{X}_{\\cdot j}-\\bar{X}\\right) \\end{aligned}\) 注意到上式第三项(即交叉项): \(2 \\sum\_{j=1}^{s} \\sum\_{i=1}^{n\_{j}}\\left(X\_{i j}-\\bar{X}_{\\cdot j}\\right)\\left(\\bar{X}_{\\cdot j}-\\bar{X}\\right)\) \(\\quad=2 \\sum\_{i j}^{s}\\left(\\bar{X}_{\\cdot j}-\\bar{X}\\right)\\left\[\\sum_{i j}^{n\_{j}}\\left(X\_{i j}-\\bar{X}_{\\cdot j}\\right)\\right\]=2 \\sum\\left(\\bar{X}_{\\cdot j}-\\bar{X}\\right)\\left(\\sum\_{i j}-n\_{j} \\bar{X}\_{\\cdot j}\\right)=0\)
平方和分解式:我们将总偏差平方和\(S\_{T}\)分解成为:\(S\_{T}=S\_{E}+S\_{A}\), 其中\(S\_{E}=\\sum\_{j=1}^{s} \\sum\_{i=1}^{n\_{j}}\\left(X\_{i j}-\\bar{X}_{\\cdot j}\\right)^{2}\),\(S_{E}\) 的各项 \(\\left(X\_{i j}-\\bar{X}_{\\cdot j}\\right)^{2}\) 表示**在水平 \(A_{j}\) 下,样本观察值与样本均值的差异** 这是由随机误差所引起的. \(S\_{E}\) 叫做误差平方和.\(,\) \(S\_{A}=\\sum\_{j=1}^{s} \\sum\_{i=1}^{n\_{j}}\\left(\\bar{X}_{\\cdot j}-\\bar{X}\\right)^{2}=\\sum_{j=1}^{s} n\_{j}\\left(\\bar{X}_{\\cdot j}-\\bar{X}\\right)^{2}=\\sum_{j=1}^{s} n\_{j} \\bar{X}_{\\cdot j}^{2}-n \\bar{X}^{2}\),\(S_{A}\) 的各项 \(n\_{j}\\left(\\bar{X}_{\\cdot j}-\\bar{X}\\right)^{2}\) 表示 **\(A_{j}\) 水平下的样本平均值与数据总平均的差异**,这是由水平 \(A\_{j}\) 的效应的差异以及随机误差引起的. \(S\_{A}\) 叫做因素 \(A\) 的效应平方和.
\(S\_{E}, S\_{A}\) 的统计特性
为了引出上面检验问题的检验统计量,我们依次来讨论 \(S\_{E}, S\_{A}\) 的一些统计特性. \(S\_{E}=\\sum\_{i=1}^{n\_{1}}\\left(X\_{i 1}-\\bar{X}_{\\cdot 1}\\right)^{2}+\\cdots+\\sum_{i=1}^{n\_{s}}\\left(X\_{i s}-\\bar{X}\_{\\cdot s}\\right)^{2}\)
注意每个j列都是一个正态总体总体 \(N\\left(\\mu\_{j}, \\sigma^{2}\\right)\), 于是有\(\\frac{\\sum\_{i=1}^{n\_{j}}\\left(X\_{i j}-\\bar{X}_{\\cdot j}\\right)^{2}}{\\sigma^{2}} \\sim \\chi^{2}\\left(n_{j}-1\\right)\)
各列(各总体)互相独立,故\(S\_{E}\)式中各平方和相互独立. 由 \(\\chi^{2}\) 分布的可加性知\(\\frac{S\_{E}}{\\sigma^{2}} \\sim \\chi^{2}\\left(\\sum\_{i=1}^{s}\\left(n\_{j}-1\\right)\\right)\), 即:\(\\frac{S\_{E}}{\\sigma^{2}} \\sim \\chi^{2}(n-s)\),
由上式还可知\(S\_{E}\) 的自由度为 \(n-s,\) 且有\(E\\left(S\_{E}\\right)=(n-s) \\sigma^{2}\)
下面讨论 \(\\mathrm{S}_{A}\) 的统计特性, \(S_{A}=\\sum\_{j=1}^{s} \\sum\_{i=1}^{n\_{j}}\\left(\\bar{X}_{\\cdot j}-\\bar{X}\\right)^{2}=\\sum_{j=1}^{s} n\_{j}\\left(\\bar{X}_{\\cdot j}-\\bar{X}\\right)^{2}=\\sum_{j=1}^{s} n\_{j} \\bar{X}_{\\cdot j}^{2}-n \\bar{X}^{2}\), 我们看到 \(\\mathrm{S}_{A}\) 是 \(s\) 个变量 \(\\sqrt{n\_{j}}\\left(\\bar{X}_{\\cdot j}-\\bar{X}\\right)(j=1\), \(2, \\cdots, s)\) 的平方和, 它们之间仅有一个线性约束条件:\(\\sum_{j=1}^{s} \\sqrt{n\_{j}}\\left\[\\sqrt{n\_{j}}\\left(\\bar{X}_{\\cdot j}-\\bar{X}\\right)\\right\]=\\sum_{j=1}^{s} n\_{j}\\left(\\bar{X}_{\\cdot j}-\\bar{X}\\right)=\\sum_{j=1}^{s} \\sum\_{i=1}^{n\_{j}} X\_{i j}-n \\bar{X}=0\), 故知 \(S\_{A}\) 的自由度是 \(s-1 .\)
由\(\\mu=\\frac{1}{n} \\sum\_{j=1}^{s} n\_{j} \\mu\_{j}\),\(\\bar{X}=\\frac{1}{n} \\sum\_{j=1}^{s} \\sum\_{i=1}^{n\_{j}} X\_{i j}\),以及\(X\_{ij}\)的独立性, 知\(\\bar{X} \\sim N\\left(\\mu, \\frac{\\sigma^{2}}{n}\\right)\)
可求得: \(\\begin{aligned} E\\left(S\_{A}\\right) \&=E\\left\[\\sum\_{j=1}^{s} n\_{j} \\bar{X}_{\\cdot j}^{2}-n \\bar{X}^{2}\\right\]=\\sum_{j=1}^{s} n\_{j} E\\left(\\bar{X}_{\\cdot j}^{2}\\right)-n E\\left(\\bar{X}^{2}\\right) \\ \&=\\sum_{j=1}^{s} n\_{j}\\left\[\\frac{\\sigma^{2}}{n\_{j}}+\\left(\\mu+\\delta\_{j}\\right)^{2}\\right\]-n\\left(\\frac{\\sigma^{2}}{n}+\\mu^{2}\\right) \\ \&=(s-1) \\sigma^{2}+2 \\mu \\sum\_{j=1}^{s} n\_{j} \\delta\_{j}+n \\mu^{2}+\\sum\_{j=1}^{s} n\_{j} \\delta\_{j}^{2}-n \\mu^{2} \\end{aligned}\) 由改写后的单因素试验方差分析的数学模型可知\(\\sum\_{j=1}^{s} n\_{j} \\delta\_{j}=0\), 即得\(E\\left(S\_{A}\\right)=(s-1) \\sigma^{2}+\\sum\_{j=1}^{s} n\_{j} \\delta\_{j}^{2}\)。
进一步还可以证明 \(S\_{A}\) 与 \(S\_{E}\) 独立,且当 \(H\_{0}\) 为真时,\(\\frac{S\_{A}}{\\sigma^{2}} \\sim \\chi^{2}(s-1)\)
假设检验问题的拒绝域
现在我们可以来确定原假设检验问题的拒绝域了.
由\(E\\left(S\_{A}\\right)=(s-1) \\sigma^{2}+\\sum\_{j=1}^{s} n\_{j} \\delta\_{j}^{2}\)知, 当 \(H\_{0}\) 为真时,\(E\\left(\\frac{S\_{A}}{s-1}\\right)=\\sigma^{2}\)。 即 \(\\frac{S\_{A}}{s-1}\) 是 \(\\sigma^{2}\) 的无偏估计. 而当 \(H\_{1}\) 为真时 \(, \\sum\_{j=1}^{s} n\_{j} \\delta\_{j}^{2}\>0,\) 此时\(E\\left(\\frac{S\_{A}}{s-1}\\right)=\\sigma^{2}+\\frac{1}{s-1} \\sum\_{j=1}^{s} n\_{j} \\delta\_{j}^{2}\>\\sigma^{2}\)
由\(E\\left(S\_{E}\\right)=(n-s) \\sigma^{2}\)知, \(E\\left(\\frac{S\_{E}}{n-s}\\right)=\\sigma^{2}\), 即不管 \(H\_{0}\) 是否为真 \(, \\frac{S\_{E}}{n-s}\) 都是 \(\\sigma^{2}\) 的无偏估计.
综上所述,分式 \(F=\\frac{S\_{A} /(s-1)}{S\_{E} /(n-s)}\) 的分子与分母独立, 分母 \(\\frac{S\_{E}}{n-s}\) 不论 \(H\_{0}\) 是否为真,其数学期望总是 \(\\sigma^{2} .\) 当 \(H\_{0}\) 为真时,分子的数学期望为 \(\\sigma^{2},\) 当 \(H\_{0}\) 不真时, 由\(E\\left(\\frac{S\_{A}}{s-1}\\right)=\\sigma^{2}+\\frac{1}{s-1} \\sum\_{j=1}^{s} n\_{j} \\delta\_{j}^{2}\>\\sigma^{2}\)知分子的取值有偏大的趋势. 故知原检验问题的拒绝域具有形式\(F=\\frac{S\_{A} /(s-1)}{S\_{E} /(n-s)} \\geqslant k\)
其中 \(k\) 由预先给定的显著性水平 \(\\alpha\) 确定. \(\\frac{S\_{E}}{\\sigma^{2}} \\sim \\chi^{2}(n-s)\),\(\\frac{S\_{A}}{\\sigma^{2}} \\sim \\chi^{2}(s-1)\),以及\(S\_{E}\) 与 \(S\_{A}\) 的独立性知, 当 \(H\_{0}\) 为真时,\(\\frac{S\_{A} /(s-1)}{S\_{E} /(n-s)}=\\frac{S\_{A} / \\sigma^{2}}{s-1} / \\frac{S\_{E} / \\sigma^{2}}{n-s} \\sim F(s-1, n-s)\) 由此得原检验问题的拒绝域为\(F=\\frac{S\_{A} /(s-1)}{S\_{E} /(n-s)} \\geqslant F\_{\\alpha}(s-1, n-s)\)
上述分析的结果可排成下面图表的形式,称为方差分析表:  图表中 \(\\bar{S}_{A}=S_{A} /(s-1), \\bar{S}_{E}=S_{E} /(n-s)\) 分别称为 \(S\_{A}, S\_{E}\) 的均方. 另外,因在\(S\_{T}\) 中 \(n\) 个变量 \(X\_{i j}-\\bar{X}\) 之间仅满足一个约束条件\(\\bar{X}=\\frac{1}{n} \\sum\_{j=1}^{s} \\sum\_{i=1}^{n\_{j}} X\_{i j}\),故 \(S\_{T}\) 的自由度为 \(n-1 .\)
图表中 \(\\bar{S}_{A}=S_{A} /(s-1), \\bar{S}_{E}=S_{E} /(n-s)\) 分别称为 \(S\_{A}, S\_{E}\) 的均方. 另外,因在\(S\_{T}\) 中 \(n\) 个变量 \(X\_{i j}-\\bar{X}\) 之间仅满足一个约束条件\(\\bar{X}=\\frac{1}{n} \\sum\_{j=1}^{s} \\sum\_{i=1}^{n\_{j}} X\_{i j}\),故 \(S\_{T}\) 的自由度为 \(n-1 .\)
在实际中,我们可以按以下较简便的公式来计算 \(S\_{T}, S\_{A}\) 和 \(S\_{E}\). 记: \(T\_{\\cdot j}=\\sum\_{i=1}^{n\_{j}} X\_{i j}, j=1,2, \\cdots, s\) \(T\_{\\cdot \\cdot}=\\sum\_{j=1}^{s} \\sum\_{i=1}^{n\_{j}} X\_{i j}\) 即有: \(\\left.\\begin{array}{l}S\_{T}=\\sum\_{j=1}^{s} \\sum\_{i=1}^{n\_{j}} X\_{i j}^{2}-n \\bar{X}^{2}=\\sum\_{j=1}^{s} \\sum\_{i=1}^{n\_{j}} X\_{i j}^{2}-\\frac{T^{2}}{n} \\ S\_{A}=\\sum\_{j=1}^{s} n\_{j} \\bar{X}_{\\cdot j}^{2}-n \\bar{X}^{2}=\\sum_{j=1}^{s} \\frac{T\_{\\cdot j}^{2}}{n\_{j}}-\\frac{T\_{\\cdots}^{2}}{n} \\ S\_{E}=S\_{T}-S\_{A}\\end{array}\\right}\)
未知参数的估计
上面已讲到过,不管 \(H\_{0}\) 是否为真,\(\\hat{\\sigma}^{2}=\\frac{S\_{E}}{n-s}\),是 \(\\sigma^{2}\) 的无偏估计. 由\(\\bar{X} \\sim N\\left(\\mu, \\frac{\\sigma^{2}}{n}\\right)\),\(\\bar{X}_{\\cdot j}=\\frac{1}{n_{j}} \\sum\_{i=1}^{n\_{j}} X\_{i j}\),知: \(E(\\bar{X})=\\mu\), \(E\\left(\\bar{X}_{\\cdot j}\\right)=\\frac{1}{n_{j}} \\sum\_{i=1}^{n\_{j}} E\\left(X\_{i j}\\right)=\\mu\_{j}, j=1,2, \\cdots, s\) 故 \(\\hat{\\mu}=\\bar{X}, \\quad \\hat{\\mu}_{j}=\\bar{X}_{\\cdot j}\) 分别是 \(\\mu, \\mu\_{j}\) 的无偏估计.
又若拒绝 \(H\_{0},\) 这意味着效应 \(\\delta\_{1}, \\delta\_{2}, \\cdots, \\delta\_{s}\) 不全为零. 由于\(\\delta\_{j}=\\mu\_{j}-\\mu, \\quad j=1,2, \\cdots, s\), 知 \(\\hat{\\delta}_{j}=\\bar{X}_{\\cdot j}-\\bar{X}\) 是 \(\\delta\_{j}\) 的无偏估计. 此时还有关系式\(\\sum\_{j=1}^{s} n\_{j} \\hat{\\delta}_{j}=\\sum_{j=1}^{s} n\_{j} \\bar{X}_{\\cdot j}-n \\bar{X}=0\) 当拒绝 \(H_{0}\) 时,常需要作出两总体 \(N\\left(\\mu\_{j}, \\sigma^{2}\\right)\) 和 \(N\\left(\\mu\_{k}, \\sigma^{2}\\right), j \\neq k\) 的均值差 \(\\mu\_j-\\mu\_{k}=\\delta\_{j}-\\delta\_{k}\) 的区间估计。做法如下: 由于\(E\\left(\\bar{X}_{\\cdot j}-\\bar{X}_{\\cdot k}\\right)=\\mu\_{j}-\\mu\_{k}\),\(D\\left(\\bar{X}_{\\cdot j}-\\bar{X}_{\\cdot k}\\right)=\\sigma^{2}\\left(\\frac{1}{n\_{j}}+\\frac{1}{n\_{k}}\\right)\), 且\(\\bar{X}_{\\cdot j}-\\bar{X}_{\\cdot k} \\frac{\\vdash\_{\\sigma} \\hat{\\sigma}^{2}}{=} S\_{E} /(n-s)\) 独立. 于是\(\\frac{\\left(\\bar{X}_{\\cdot j}-\\bar{X}_{\\cdot k}\\right)-\\left(\\mu\_{j}-\\mu\_{k}\\right)}{\\bar{S}_{E}\\left(\\frac{1}{n_{j}}+\\frac{1}{n\_{k}}\\right)}\) \(\\quad=\\frac{\\left(\\bar{X}_{\\cdot j}-\\bar{X}_{\\cdot k}\\right)-\\left(\\mu\_{j}-\\mu\_{k}\\right)}{\\sigma \\sqrt{1 / n\_{j}+1 / n\_{k}}} / \\sqrt{\\frac{S\_{E}}{\\sigma^{2}} /(n-s)} \\sim t(n-s)\) 据此得均值差 \(\\mu\_{j}-\\mu\_{k}=\\delta\_{j}-\\delta\_{k}\) 的置信水平为 \(1-\\alpha\) 的置信区间为: \(\\left(\\bar{X}_{\\cdot j}-\\bar{X}_{\\cdot k} \\pm t\_{a / 2}(n-s) \\sqrt{\\bar{S}_{E}\\left(\\frac{1}{n_{j}}+\\frac{1}{n\_{k}}\\right)}\\right)\)
双因素试验的方差分析
//TODO
一元线性回归
在客观世界中普遍存在着变量之间的关系变量之间的关系。一般来说可分为确定性的与非确定性的两种。 确定性关系是指变量之间的关系可以用函数关系来表达的。 另一种非确定性的关系即所谓相关关系。例如人的身高与体重之间存在着关系,一般来说,人高一些,体重要重一些,但同样高度的人,体重往往不相同。人的血压与年龄之间也存在着关系,但同年龄的人的血压往往不相同。气象中的温度与湿度之间的关系也是这样。这是因为我们涉及的变量(如体重、血压、湿度)是随机变量,上面所说的变量关系是非确定性的回归分析是研究相关关系的一种数学工具。它能帮助我们从一个变量取得的值去估计另一变量所取的值。
一元线性回归模型
设随机变量 \(Y\) 与 \(x\) 之间存在着某种相关关系. 这里, \(x\) 是可以控制或可以精确观察的变量,如年龄、试验时的温度、施加的压力、电压与时间等.换句话说我 们可以随意指定 \(n\) 个值 \(x\_{1}, x\_{2}, \\cdots, x\_{n} .\) 因此我们干脆不把 \(x\) 看成是随机变量,而 将它当作普通的变量. 本章中我们只讨论这种情况.
设随机变量 Y(因变量)与普通变量 \(x\) (自变量) 之间存在着相关关系,由于 \(Y\)是随机变量,对于 \(x\) 的各个确定值,Y 有它 的分布如下图: 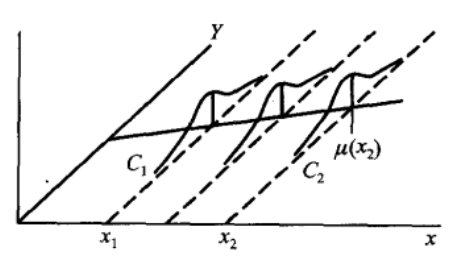 (图中 \(C\_{1}, C\_{2}\) 分别是 \(x\_{1}\),\(x\_{2}\) 处 \(Y\) 的概率密度曲线 \() .\) 用 \(F(y \\mid x)\) 表示 当 \(x\) 取确定的 \(x\) 值时,所对应的 \(Y\) 的分布函数,如果我们掌握了 \(F(y \\mid x)\) 随着 \(x\) 的 取值而变化的规律,那么就能完全掌握 Y与 \(x\) 之间的关系了. 然而这样做往往比较复杂.
(图中 \(C\_{1}, C\_{2}\) 分别是 \(x\_{1}\),\(x\_{2}\) 处 \(Y\) 的概率密度曲线 \() .\) 用 \(F(y \\mid x)\) 表示 当 \(x\) 取确定的 \(x\) 值时,所对应的 \(Y\) 的分布函数,如果我们掌握了 \(F(y \\mid x)\) 随着 \(x\) 的 取值而变化的规律,那么就能完全掌握 Y与 \(x\) 之间的关系了. 然而这样做往往比较复杂.
作为一种近似,我们转而去考察 \(Y\) 的数学期望,若 \(Y\) 的数学期望 \(E(Y)\) 存在,则其值随 \(x\) 的取值而定,它是 \(x\) 的函 数. 将这一函数记为 \(\\mu\_{Y \\mid x}\) 或 \(\\mu(x)\),称为 \(Y\) 关于 \(x\) 的回归函数(如上图中所示). 这样, 我们就将讨论 \(Y\) 与 \(x\) 的相关关系的问题转换为讨论 \(E(Y)=\\mu(x)\) 与 \(x\) 的函数关系了.
我们知道,若 \(\\eta\) 是一个随机变量,则 \(E\\left\[(\\eta-c)^{2}\\right\]\) 作为 \(c\) 的函数,在 \(c=E(\\eta)\) 时 \(E\\left\[(\\eta-c)^{2}\\right\]\) 达到踏小(参见第四章习题第 17 题). 这表明在一切 \(x\) 的函数中以 回归函数 \(\\mu(x)\) 作为 \(Y\) 的近似,其均方误差 \(E\\left\[(Y-\\mu(x))^{2}\\right\]\) 为最小. 因此,作为一 种近似,为了研究 \(Y\) 与 \(x\) 的关系转而去研究 \(\\mu(x)\) 与 \(x\) 的关系是合适的.
在实际问题中,回归函数 \(\\mu(x)\) 一般是未知的, 回归分析的任务是在于根据 试验数据去估计回归函数,讨论有关的点估计、区间估计、假设检验等问题. 特别重要的是对随机变量 \(Y\) 的观察值作出点预测和区间预测.
我们对于 \(x\) 取定一组不完全相同的值 \(x\_{1}, x\_{2}, \\cdots, x\_{n},\) 设 \(Y\_{1}, Y\_{2}, \\cdots, Y\_{n}\) 分别是 在 \(x\_{1}, x\_{2}, \\cdots, x\_{n}\) 处对 \(Y\) 的独立观察结果,称\(\\left(x\_{1}, Y\_{1}\\right),\\left(x\_{2}, Y\_{2}\\right), \\cdots,\\left(x\_{n}, Y\_{n}\\right)\)是一个样本 , 对应的样本值记为\(\\left(x\_{1}, y\_{1}\\right),\\left(x\_{2}, y\_{2}\\right), \\cdots,\\left(x\_{n}, y\_{n}\\right)\)
注意:这里 \(Y\_{1}, Y\_{2}, \\cdots, Y\_{n}\) 是相互独立的随机变量,但一般未必同分布,为方便计,也称 \(\\left(x\_{1}, Y\_{1}\\right),\\left(x\_{2},\\right.\) \(\\left.Y\_{2}\\right), \\cdots,\\left(x\_{n}, Y\_{n}\\right)\) 是一个样本.
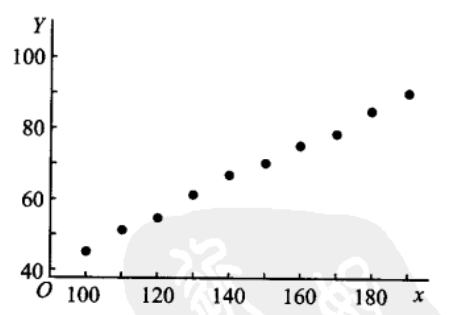
我们首先要解决的问题是如何利用样本来估计 \(Y\) 关于 \(x\) 的回归函数 \(\\mu(x) .\) 为此,首先需要推测 \(\\mu(x)\) 的形式. 在一些问题中,我们可以由专业知识知道 \(\\mu(x)\) 的形式. 否则 \(,\) 可将每对观察值 \(\\left(x\_{i}, y\_{i}\\right)\) 在直角坐标系中描出它的相应的点(如下例子图所示),这种图称为散点图. 散点图可以帮助我们粗略地看出 \(\\mu(x)\) 的 形式.
例子: 为研究某一化学反应过程中,温度 \(x\\left({ }^{\\circ} \\mathrm{C}\\right)\) 对产品得率 \(Y(%)\) 的影响,测得数据如下:
这里自变量 \(x\) 是普通变量, \(Y\) 是随机变 量.画出散点图如下图所示. 由图大致看出 \(\\mu(x)\) 具有线性函数 \(a+b x\) 的形 式.
设 \(Y\) 关于 \(x\) 的回归函数为 \(\\mu(x) .\) 利 用样本来估计 \(\\mu(x)\) 的问题称为求 \(Y\) 关 于 \(x\) 的回归问题. 特别,若 \(\\mu(x)\) 为线性 函数 \(: \\mu(x)=a+b x,\) 此时估计 \(\\mu(x)\) 的 问题称为求一元线性回归问题. 本节只讨论这个问题.
我们假设对于 \(x\) (在某个区间内) 的每一个值有\(Y \\sim N\\left(a+b x, \\sigma^{2}\\right)\), 其中 \(a, b\) 及 \(\\sigma^{2}\) 都是不依赖于 \(x\) 的未知参数. 记 \(\\varepsilon=Y-(a+b x)\),对 \(Y\) 作这样的正态假设,相当于假设: \(Y=a+b x+\\varepsilon, \\quad \\varepsilon \\sim N\\left(0, \\sigma^{2}\\right)\), 其中未知参数 \(a, b\) 及 \(\\sigma^{2}\) 都不依赖于 \(x .\) (3. 2 ) 称为一元线性回归模型,其中 \(b\) 称为回归系数.
上面的一元线性回归模型表明,因变量 \(Y\) 由两部分组成,一部分是 \(x\) 的线性函数 \(a+b x,\) 另一部分 \(\\varepsilon \\sim N\\left(0, \\sigma^{2}\\right)\) 是随机误差,是人们不可控制的.
\(a, b\) 的估计
现用最大似然估计法来估计未知参数 \(a, b .\)
取 \(x\) 的 \(n\) 个不全相同的值 \(x\_{1}, x\_{2}, \\cdots, x\_{n}\) 作独立试验,得到样本 \(\\left(x\_{1}, Y\_{1}\\right),\\left(x\_{2},\\right.\\left.Y\_{2}\\right), \\cdots,\\left(x\_{n}, Y\_{n}\\right) .\) 由一元线性回归模型得\(Y\_{i}=a+b x\_{i}+\\varepsilon\_{i}, \\varepsilon\_{i} \\sim N\\left(0, \\sigma^{2}\\right),\) 各 \(\\varepsilon\_{i}\) 相互独立. 也即 \(Y\_{i} \\sim N\\left(a+b x\_{i}, \\sigma^{2}\\right), i=1,2, \\cdots, n .\)
由 \(Y\_{1}, Y\_{2}, \\cdots, Y\_{n}\) 的独立性, 知 \(Y\_{1},\)\(Y\_{2}, \\cdots, Y\_{n}\) 的联合密度为: \(\\begin{aligned} L \&=\\prod\_{i=1}^{n} \\frac{1}{\\sigma \\sqrt{2 \\pi}} \\exp \\left\[-\\frac{1}{2 \\sigma^{2}}\\left(y\_{i}-a-b x\_{i}\\right)^{2}\\right\] \\ \&=\\left(\\frac{1}{\\sigma \\sqrt{2 \\pi}}\\right)^{n} \\exp \\left\[-\\frac{1}{2 \\sigma^{2}} \\sum\_{i=1}^{n}\\left(y\_{i}-a-b x\_{i}\\right)^{2}\\right\] \\end{aligned}\)
对于任意一组观察值 \(y\_{1}, y\_{2}, \\cdots, y\_{n},\) 联合密度函数L就是样本的似然函数. 显然,要 \(L\) 取最大值,只要L式右端方括弧中的平方和部分为最小,即只需函数\(Q(a, b)=\\sum\_{i=1}^{n}\\left(y\_{i}-a-b x\_{i}\\right)^{2}\)取最小值。 取 \(Q\) 分别关于 \(a, b\) 的偏导数,并令它们等于零: \(\\left.\\begin{array}{l}\\frac{\\partial Q}{\\partial a}=-2 \\sum\_{i=1}^{n}\\left(y\_{i}-a-b x\_{i}\\right)=0 \\ \\frac{\\partial Q}{\\partial b}=-2 \\sum\_{i=1}^{n}\\left(y\_{i}-a-b x\_{i}\\right) x\_{i}=0\\end{array}\\right}\) 得方程组(称为正规方程组): \(\\left{\\begin{array}{l}n a+\\left(\\sum\_{i=1}^{n} x\_{i}\\right) b=\\sum\_{i=1}^{n} y\_{i} \\ \\left(\\sum\_{i=1}^{n} x\_{i}\\right) a+\\left(\\sum\_{i=1}^{n} x\_{i}^{2}\\right) b=\\sum\_{i=1}^{n} x\_{i} y\_{i}\\end{array}\\right.\) 由于 \(x\_{i}\) 不全相同,正规方程组的系数行列式: \(\\left|\\begin{array}{cc}n \& \\sum\_{i=1}^{n} x\_{i} \\ \\sum\_{i=1}^{n} x\_{i} \& \\sum\_{i=1}^{n} x\_{i}^{2}\\end{array}\\right|=n \\sum\_{i=1}^{n} x\_{i}^{2}-\\left(\\sum\_{i=1}^{n} x\_{i}\\right)^{2}=n \\sum\_{i=1}^{n}\\left(x\_{i}-\\bar{x}\\right)^{2} \\neq 0\) 于是正规方程组有唯一的一组解. 解得 \(b, a\) 的最大似然估计值为 \(\\left.\\begin{array}{l}\\hat{b}=\\frac{n \\sum\_{i=1}^{n} x\_{i} y\_{i}-\\left(\\sum\_{i=1}^{n} x\_{i}\\right)\\left(\\sum\_{i=1}^{n} y\_{i}\\right)}{n \\sum\_{i=1}^{n} x\_{i}^{2}-\\left(\\sum\_{i=1}^{n} x\_{i}\\right)^{2}}=\\frac{\\sum\_{i=1}^{n}\\left(x\_{i}-\\bar{x}\\right)\\left(y\_{i}-\\bar{y}\\right)}{\\sum\_{i=1}^{n}\\left(x\_{i}-\\bar{x}\\right)^{2}} \\ \\hat{a}=\\frac{1}{n} \\sum\_{i=1}^{n} y\_{i}-\\frac{\\hat{b}}{n} \\sum\_{i=1}^{n} x\_{i}=\\bar{y}-\\hat{b} \\bar{x}\\end{array}\\right}\) 其中 \(\\bar{x}=\\frac{1}{n} \\sum\_{i=1}^{n} x\_{i}, \\quad \\bar{y}=\\frac{1}{n} \\sum\_{i=1}^{n} y\_{i}\)
为了理解和计算的方便,引入以下记号: \(\\left.\\begin{array}{l}S\_{x x}=\\sum\_{i=1}^{n}\\left(x\_{i}-\\bar{x}\\right)^{2}=\\sum\_{i=1}^{n} x\_{i}^{2}-\\frac{1}{n}\\left(\\sum\_{i=1}^{n} x\_{i}\\right)^{2} \\ S\_{y y}=\\sum\_{i=1}^{n}\\left(y\_{i}-\\bar{y}\\right)^{2}=\\sum\_{i=1}^{n} y\_{i}^{2}-\\frac{1}{n}\\left(\\sum\_{i=1}^{n} y\_{i}\\right)^{2} \\ S\_{x y}=\\sum\_{i=1}^{n}\\left(x\_{i}-\\bar{x}\\right)\\left(y\_{i}-\\bar{y}\\right)=\\sum\_{i=1}^{n} x\_{i} y\_{i}-\\frac{1}{n}\\left(\\sum\_{i=1}^{n} x\_{i}\\right)\\left(\\sum\_{i=1}^{n} y\_{i}\\right)\\end{array}\\right}\) 这样a,b的估计可以简记为: \(\\left.\\begin{array}{l}\\hat{b}=\\frac{S\_{x y}}{S\_{x x}} \\ \\hat{a}=\\bar{y}-\\hat{b} \\bar{x}\\end{array}\\right}\)
注意:如果 Y不且正态变量,可直接用\(Q(a, b)=\\sum\_{i=1}^{n}\\left(y\_{i}-a-b x\_{i}\\right)^{2}\)估计 \(a, b,\) 使 \(Y\) 的观察值 \(y\_{i}\) 与 \(a+b x\_{i}\) 偏差的平方和 \(Q (a,b)\)为最小.这种方法叫最小二乘法,它是求经验公式的一种常用方法. 若 \(Y\) 是正态变量,则最小二乘法与最大似然估计法给出相同的结果.
在得到 \(a, b\) 的估计 \(\\hat{a}, \\hat{b}\) 后,对于给定的 \(x,\) 我们就取 \(\\hat{a}+\\hat{b} x\) 作为回归函数 \(\\mu(x)=a+b x\) 的估计, 即 \(\\mu(x)=\\hat{a}+\\hat{b} x\),称为 \(Y\) 关于 \(x\) 的经验回归函数. 记 \(\\hat{a}+\\hat{b} x\) \(=\\hat{y},\) 方程\(\\hat{y}=\\hat{a}+\\hat{b} x\)称为 \(Y\) 关于 \(x\) 的经验回归方程,简称回归方程,其图形称为回归直线.
将 \(\\hat{a}\) 的表达式代入\(\\hat{y}=\\hat{a}+\\hat{b} x\),则回归方程可写成\(\\hat{y}=\\bar{y}+\\hat{b}(x-\\bar{x})\), 这表明,对于样本值 \(\\left(x\_{1}, y\_{1}\\right),\\left(x\_{2}, y\_{2}\\right), \\cdots,\\left(x\_{n}, y\_{n}\\right),\) 回归直线通过散点图的几何中心 \((\\bar{x}, \\bar{y})\).
\(\\sigma^{2}\) 的估计
由\(Y=a+b x+\\varepsilon, \\quad \\varepsilon \\sim N\\left(0, \\sigma^{2}\\right)\)可知: \(E\\left{\[Y-(a+b x)\]^{2}\\right}=E\\left(\\varepsilon^{2}\\right)=D(\\varepsilon)+\[E(\\varepsilon)\]^{2}=\\sigma^{2}\)
这表示 \(\\sigma^{2}\) 愈小,以回归函数 \(\\mu(x)=a+b x\) 作为 \(Y\) 的近似导致的均方误差就愈小. 这样,利用回归函数 \(\\mu(x)=a+b x\) 去研究随机变量 \(Y\) 与 \(x\) 的关系就愈有效. 然而 \(\\sigma^{2}\) 是未知的,因而我们需要利用样本去估计 \(\\sigma^{2} .\) 为了估计 \(\\sigma^{2},\) 先引入下述残差平方和.
记 \(\\hat{y}_{i}=\\left.\\hat{y}\\right|_{x=x\_{i}}=\\hat{a}+\\hat{b} x\_{i},\) 称\(y\_{i}-\\hat{y}_{i}\) 为 \(x_{i}\) 处的残差. 平方和\(Q\_{e}=\\sum\_{i=1}^{n}\\left(y\_{i}-\\hat{y}_{i}\\right)^{2}=\\sum_{i=1}^{n}\\left(y\_{i}-\\hat{a}-\\hat{b} x\_{i}\\right)^{2}\)称为残差平方和. 它是经验回归函数在 \(x\_{i}\) 处的函数值 \(\\mu\\left(x\_{i}\\right)=\\hat{a}+\\hat{b} x\_{i}\) 与 \(x\_{i}\) 处的观察值 \(y\_{i}\) 的 偏差的平方和. 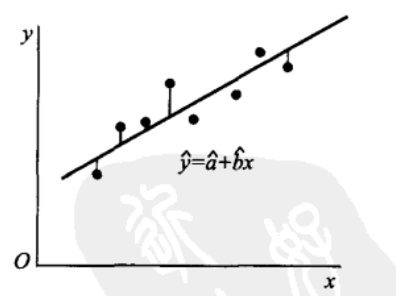 为了计算 \(Q\_{e},\) 我们将 \(Q\_{e}\) 作如下的分解 : \(\\begin{aligned} Q\_{e}=\& \\sum\_{i=1}^{n}\\left(y\_{i}-\\hat{y}_{i}\\right)^{2}=\\sum_{i=1}^{n}\\left\[y\_{i}-\\bar{y}-\\hat{b}\\left(x\_{i}-\\bar{x}\\right)\\right\]^{2} =\& \\sum\_{i=1}^{n}\\left(y\_{i}-\\bar{y}\\right)^{2}-2 \\hat{b} \\sum\_{i=1}^{n}\\left(x\_{i}-\\bar{x}\\right)\\left(y\_{i}-\\bar{y}\\right) \\ \&+(\\hat{b})^{2} \\sum\_{i=1}^{n}\\left(x\_{i}-\\bar{x}\\right)^{2}=S\_{y y}-2 \\hat{b} S\_{x y}+(\\hat{b})^{2} S\_{x x} \\end{aligned}\)
为了计算 \(Q\_{e},\) 我们将 \(Q\_{e}\) 作如下的分解 : \(\\begin{aligned} Q\_{e}=\& \\sum\_{i=1}^{n}\\left(y\_{i}-\\hat{y}_{i}\\right)^{2}=\\sum_{i=1}^{n}\\left\[y\_{i}-\\bar{y}-\\hat{b}\\left(x\_{i}-\\bar{x}\\right)\\right\]^{2} =\& \\sum\_{i=1}^{n}\\left(y\_{i}-\\bar{y}\\right)^{2}-2 \\hat{b} \\sum\_{i=1}^{n}\\left(x\_{i}-\\bar{x}\\right)\\left(y\_{i}-\\bar{y}\\right) \\ \&+(\\hat{b})^{2} \\sum\_{i=1}^{n}\\left(x\_{i}-\\bar{x}\\right)^{2}=S\_{y y}-2 \\hat{b} S\_{x y}+(\\hat{b})^{2} S\_{x x} \\end{aligned}\)
由b的估计\(\\left.\\begin{array}{l}\\hat{b}=\\frac{S\_{x y}}{S\_{x x}} \\ \\hat{a}=\\bar{y}-\\hat{b} \\bar{x}\\end{array}\\right}\),将\(\\hat{b}\)代入\(Q\_e\)得:
\(Q\_{e}=S\_{y y}-\\hat{b} S\_{x y}\)
在 \(S\_{x y}, S\_{x y}\) 的表达式式中,将 \(y\_{i}\) 改为 \(Y\_{i}\)\((i=1,2, \\cdots, n),\) 并把它们分别记为 \(S\_{Y Y}, S\_{x Y},\) 即\(S\_{Y Y}=\\sum\_{i=1}^{n}\\left(Y\_{i}-\\bar{Y}\\right)^{2}, S\_{x Y}=\\sum\_{i=1}^{n}\\left(x\_{i}-\\bar{x}\\right)\\left(Y\_{i}-\\bar{Y}\\right)\)
则残差平方和 \(Q\_{e}\) 的相应的统计量(仍记为 \(\\left.Q\_{e}\\right)\) 为\(Q\_{e}=S\_{Y Y}-\\hat{b} S\_{x Y}\)
残差平方和 \(Q\_{e}\) 服从分布\(\\frac{Q\_{e}}{\\sigma^{2}} \\sim \\chi^{2}(n-2)\), 于是\(E\\left(\\frac{Q\_{e}}{\\sigma^{2}}\\right)=n-2\) 即知 \(E\\left(Q\_{e} /(n-2)\\right)=\\sigma^{2} .\) 这样就得到了 \(\\sigma^{2}\) 的无偏估计量 :\(\\widehat{\\sigma}^{2}=\\frac{Q\_{e}}{n-2}=\\frac{1}{n-2}\\left(S\_{Y Y}-\\hat{b} S\_{x Y}\\right)\)
线性假设的显著性检验
在以上的讨论中,我们假定 \(Y\) 关于 \(x\) 的回归 \(\\mu(x)\) 具有形式 \(a+b x\), 在处理实际问题时 \(, \\mu(x)\) 是否为 \(x\) 的线性函数,首先要根据有关专业知识和实践来判断, 其次就要根据实际观察得到的数据运用假设检验的方法来判断. 这就是说,求得的线性回归方程是否具有实用价值,一般来说,需要经过假设检验才能确定. 若线性假设\(Y=a+b x+\\varepsilon, \\quad \\varepsilon \\sim N\\left(0, \\sigma^{2}\\right)\)符合实际,则 \(b\) 不应为零,因为若 \(b=0,\) 则 \(E(Y)=\\mu(x)\) 就不依赖于 \(x\) 了. 因此我们需要检验假设\(\\begin{array}{ll}H\_{0}: \& b=0 \\ H\_{1}: \& b \\neq 0\\end{array}\), 我们使用 \(t\) 检验法来进行检验. 我们有\(\\hat{b} \\sim N\\left(b, \\sigma^{2} / S\_{x x}\\right)\)。 又由\(\\frac{Q\_{e}}{\\sigma^{2}} \\sim \\chi^{2}(n-2)\),\(\\hat{\\sigma}^{2}=\\frac{Q\_{e}}{n-2}=\\frac{1}{n-2}\\left(S\_{Y Y}-\\hat{b} S\_{x Y}\\right)\), 知\(\\frac{(n-2) \\hat{\\sigma}^{2}}{\\sigma^{2}}=\\frac{Q\_{e}}{\\sigma^{2}} \\sim \\chi^{2}(n-2)\)
且 \(\\hat{b}\) 与 \(Q\_{e}\) 独立,故有\(\\frac{\\hat{b}-b}{\\sqrt{\\sigma^{2} / S\_{x x}}} / \\sqrt{\\frac{(n-2) \\hat{\\sigma}^{2}}{\\sigma^{2}} /(n-2)} \\sim t(n-2)\) 即\(\\frac{\\hat{b}-b}{\\hat{\\sigma}} \\sqrt{S\_{x x}} \\sim t(n-2)\)
当 \(H\_{0}\) 为真时 \(b=0,\) 此时\(t=\\frac{\\hat{b}}{\\hat{\\sigma}} \\sqrt{S\_{x x}} \\sim t(n-2)\)。 且 \(E(\\hat{b})=b=0,\) 即得 \(H\_{0}\) 的拒绝域为\(|t|=\\frac{|\\hat{b}|}{\\hat{\\sigma}} \\sqrt{S\_{x x}} \\geqslant t\_{a / 2}(n-2)\),此处 \(\\alpha\) 为显著性水平.
当假设 \(H\_{0}: b=0\) 被拒绝时,认为回归效果是显著的,反之,就认为回归效果 不显著. 回归效果不显著的原因可能有如下几种: \(1^{\\circ}\) 影响 \(Y\) 取值的,除 \(x\) 及随机误差外还有其他不可忽略的因素. \(2^{\\circ} E(Y)\) 与 \(x\) 的关系不是线性的,而存在着其他的关系. \(3^{\\circ} Y\) 与 \(x\) 不存在关系.
因此需要进一步的分析原因,分别处理.
系数 \(b\) 的置信区间
当回归效果显著时,我们常需要对系数 \(b\) 作区间估计. 事实上,可由\(\\frac{\\hat{b}-b}{\\hat{\\sigma}} \\sqrt{S\_{x x}} \\sim t(n-2)\)得到 \(b\) 的置信水平为 \(1-\\alpha\) 的置信区间为\(\\left(\\hat{b} \\pm t\_{a / 2}(n-2) \\times \\frac{\\hat{\\sigma}}{\\sqrt{S\_{x x}}}\\right)\)
回归函数 \(\\mu(x)=a+b x\) 函数值的点估计和置信区间
设 \(x\_{0}\) 是自变量 \(x\) 的某一指定值. 根据回归方程\(\\hat{y}=\\hat{a}+\\hat{b} x\),可以用经验回归函数 \(\\hat{y}=\\widehat{\\mu(x)}\) \(=\\hat{a}+\\hat{b} x\) 在 \(x\_{0}\) 的函数值 \(\\left.\\hat{y}_{0}=\\mu \\widehat{\\left(x_{0}\\right.}\\right)=\\hat{a}+\\hat{b} x\_{0}\) 作为 \(\\mu\\left(x\_{0}\\right)=a+b x\_{0}\) 的点估计. 即\(\\hat{y}_{0}=\\mu\\left(x_{0}\\right)=\\hat{a}+\\hat{b} x\_{0}\), 考虑相应的估计量\(\\hat{Y}_{0}=\\hat{a}+\\hat{b} x_{0}\), 由\(\\hat{Y}_{0}=\\hat{a}+\\hat{b} x_{0}=\\bar{Y}+\\hat{b}\\left(x\_{0}-\\bar{x}\\right) \\sim N\\left(a+b x\_{0},\\left\[\\frac{1}{n}+\\frac{\\left(x\_{0}-\\bar{x}\\right)^{2}}{S\_{x r}}\\right\] \\sigma^{2}\\right)\), 知\(E\\left(\\hat{Y}_{0}\\right)=a+b x_{0},\) 因此这一估计量是无偏的.
下面来求 \(\\mu\\left(x\_{0}\\right)\)\(=a+b x\_{0}\) 的置信区间. 由\(\\hat{Y}_{0}=\\hat{a}+\\hat{b} x_{0}=\\bar{Y}+\\hat{b}\\left(x\_{0}-\\bar{x}\\right) \\sim N\\left(a+b x\_{0},\\left\[\\frac{1}{n}+\\frac{\\left(x\_{0}-\\bar{x}\\right)^{2}}{S\_{x r}}\\right\] \\sigma^{2}\\right)\), 知\(\\frac{\\hat{Y}_{0}-\\left(a+b x_{0}\\right)}{\\sigma \\sqrt{\\frac{1}{n}+\\frac{\\left(x\_{0}-\\bar{x}\\right)^{2}}{S\_{x x}}}} \\sim N(0,1)\)
由\(\\frac{Q\_{e}}{\\sigma^{2}} \\sim \\chi^{2}(n-2)\),\(\\hat{\\sigma}^{2}=\\frac{Q\_{e}}{n-2}=\\frac{1}{n-2}\\left(S\_{Y Y}-\\hat{b} S\_{x Y}\\right)\), 知\(\\frac{(n-2) \\hat{\\sigma}^{2}}{\\sigma^{2}}=\\frac{Q\_{e}}{\\sigma^{2}} \\sim \\chi^{2}(n-2)\)
若 \(Y\_{0}=a+b x\_{0}+\\varepsilon\_{0}\) 与 \(Y\_{1}, \\cdots, Y\_{n}\) 独立,则 \(Y\_{0}, \\hat{Y}_{0}, Q\_e\) 相互独立. 由上述结论知 \(Q_{e}, \\hat{Y}_{0}\) 相互独立. 于是\(\\frac{\\hat{Y}_{0}-\\left(a+b x\_{0}\\right)}{\\sigma \\sqrt{\\frac{1}{n}+\\frac{\\left(x\_{0}-\\bar{x}\\right)^{2}}{S\_{x x}}}} / \\sqrt{\\frac{(n-2) \\hat{\\sigma}^{2}}{\\sigma^{2}} /(n-2)} \\sim t(n-2)\) 即\(\\frac{\\hat{Y}_{0}-\\left(a+b x_{0}\\right)}{\\hat{\\sigma} \\sqrt{\\frac{1}{n}+\\frac{\\left(x\_{0}-\\bar{x}\\right)^{2}}{S\_{x x}}}} \\sim t(n-2)\)
于是得到 \(\\mu\\left(x\_{0}\\right)=a+b x\_{0}\) 的置信水平为 \(1-\\alpha\) 的置信区间为\(\\left(\\hat{Y}_{0} \\pm t_{\\alpha / 2}(n-2) \\hat{\\sigma} \\sqrt{\\frac{1}{n}+\\frac{\\left(x\_{0}-\\bar{x}\\right)^{2}}{S\_{x x}}}\\right)\), 或即\(\\left(\\hat{a}+\\hat{b} x\_{0} \\pm t\_{a / 2}(n-2) \\hat{\\sigma} \\sqrt{\\frac{1}{n}+\\frac{\\left(x\_{0}-\\bar{x}\\right)^{2}}{S\_{x x}}}\\right)\) 这一置信区间的长度是 \(x\_{0}\) 的函数,它随 \(\\left|x\_{0}-\\bar{x}\\right|\) 的增加而增加 \(,\) 当 \(x\_{0}=\\bar{x}\) 时为 最短.
\(Y\) 的观察值的点预测和预测区间
若我们对指定点 \(x=x\_{0}\) 处因变量 \(Y\) 的观察值 \(Y\_{0}\) 感兴趣,然而我们在 \(x=x\_{0}\) 处并未进行观察或者暂时无法观察. 经验回归函数的一个重要应用是,可利用它对因变量 \(Y\) 的新观察值 \(Y\_{0}\) 进行点预测或区间预测. 若 \(Y\_{0}\) 是在 \(x=x\_{0}\) 处对 \(Y\) 的观察结果,可知它满足 :\(Y\_{0}=a+b x\_{0}+\\varepsilon\_{0}, \\quad \\varepsilon\_{0} \\sim N\\left(0, \\sigma^{2}\\right)\) 随机误差 \(\\varepsilon\_{0}\) 可正也可负,其值无法预料,我们就用 \(x\_{0}\) 处的经验回归函数值\(\\hat{Y}_{0}=\\mu\\left(x_{0}\\right)=\\hat{a}+\\hat{b} x\_{0}\)作为 \(Y\_{0}=a+b x\_{0}+\\varepsilon\_{0}\) 的点预测.
下面来求 \(Y\_{0}\) 的预测区间.
因 \(Y\_{0}\) 是将要做的一次独立试验的结果,因此它与已经得到的试验的结果\(Y\_{1}, Y\_{2}, \\cdots, Y\_{n}\) 相互独立. 由这样a,b的估计\(\\left.\\begin{array}{l}\\hat{b}=\\frac{S\_{x y}}{S\_{x x}} \\ \\hat{a}=\\bar{y}-\\hat{b} \\bar{x}\\end{array}\\right}\)知 \(\\hat{b}\) 是 \(Y\_{1}, Y\_{2}, \\cdots, Y\_{n}\) 的线性组合, 故 \(\\hat{Y}_{0}=\)\(\\bar{Y}+\\hat{b}\\left(x_{0}-\\bar{x}\\right)\) 是 \(Y\_{1}, Y\_{2}, \\cdots, Y\_{n}\) 的线性组合,故 \(Y\_{0}\) 与 \(\\hat{Y}_{0}\) 相互独立. 由 \(Y_{0}=a+b x\_{0}+\\varepsilon\_{0}, \\quad \\varepsilon\_{0} \\sim N\\left(0, \\sigma^{2}\\right)\)和\(\\hat{Y}_{0}=\\hat{a}+\\hat{b} x_{0}=\\bar{Y}+\\hat{b}\\left(x\_{0}-\\bar{x}\\right) \\sim N\\left(a+b x\_{0},\\left\[\\frac{1}{n}+\\frac{\\left(x\_{0}-\\bar{x}\\right)^{2}}{S\_{s x}}\\right\] \\sigma^{2}\\right)\), 得\(\\hat{Y}_{0}-Y_{0} \\sim N\\left(0,\\left\[1+\\frac{1}{n}+\\frac{\\left(x\_{0}-\\bar{x}\\right)^{2}}{S\_{x x}}\\right\] \\sigma^{2}\\right)\), 即\(\\frac{\\hat{Y}_{0}-Y_{0}}{\\sigma \\sqrt{1+\\frac{1}{n}+\\frac{\\left(x\_{0}-\\bar{x}\\right)^{2}}{S\_{x x}}}} \\sim N(0,1)\)
再由\(\\frac{(n-2) \\hat{\\sigma}^{2}}{\\sigma^{2}}=\\frac{Q\_{e}}{\\sigma^{2}} \\sim \\chi^{2}(n-2)\),及 \(Y\_{0}, \\hat{Y}_{0}, Q_{.}\) 的相互独立性 知\(\\frac{\\hat{Y}_{0}-Y_{0}}{\\sigma \\sqrt{1+\\frac{1}{n}+\\frac{\\left(x\_{0}-\\bar{x}\\right)^{2}}{S\_{x x}}}} / \\sqrt{\\frac{(n-2) \\hat{\\sigma}^{2}}{\\sigma^{2}} /(n-2)} \\sim t(n-2)\) 即\(\\frac{\\hat{Y}_{0}-Y_{0}}{\\hat{\\sigma} \\sqrt{1+\\frac{1}{n}+\\frac{\\left(x\_{0}-\\bar{x}\\right)^{2}}{S\_{x x}}}} \\sim t(n-2)\)
于是对于给定的置信水平 \(1-\\alpha\) 有\(P\\left{\\frac{\\left|\\hat{Y}_{0}-Y_{0}\\right|}{\\hat{\\sigma} \\sqrt{1+\\frac{1}{n}+\\frac{\\left(x\_{0}-\\bar{x}\\right)^{2}}{S\_{x x}}}} \\leqslant t\_{a / 2}(n-2)\\right}=1-\\alpha\) 或\(P\\left{\\hat{Y}_{0}-t_{a / 2}(n-2) \\hat{\\sigma} \\sqrt{1+\\frac{1}{n}+\\frac{\\left(x\_{0}-\\bar{x}\\right)^{2}}{S\_{x x}}}\<Y\_{0}\\right.\)\(\\left.\<\\hat{Y}_{0}+t_{a / 2}(n-2) \\hat{\\sigma} \\sqrt{1+\\frac{1}{n}+\\frac{\\left(x\_{0}-\\bar{x}\\right)^{2}}{S\_{x x}}}\\right}=1-\\alpha\)
则区间\(\\left(\\hat{Y}_{0} \\pm t_{a / 2}(n-2) \\hat{\\sigma} \\sqrt{1+\\frac{1}{n}+\\frac{\\left(x\_{0}-\\bar{x}\\right)^{2}}{S\_{x x}}}\\right)\), 即\(\\left(\\hat{a}+\\hat{b} x\_{0} \\pm t\_{a / 2}(n-2) \\hat{\\sigma} \\sqrt{\\left.1+\\frac{1}{n}+\\frac{\\left(x\_{0}-\\bar{x}\\right)^{2}}{S\_{x x}}\\right)}\\right.\)称为\(Y\_{0}\) 的置信水平为 \(1-\\alpha\) 的预测区间.
这一预测区间的长度是 \(x\_{0}\) 的函数,它随 \(\\left|x\_{0}-\\bar{x}\\right|\) 的增加而增加. 当 \(x\_{0}=\\bar{x}\) 时为最短. 将上面得区间与回归函数\(\\mu\\left(x\_{0}\\right)=a+b x\_{0}\) 的置信区间比较, 知道在相同的置信水平下,回归函数值 \(\\mu\\left(x\_{0}\\right)\) 的置信区间要比 \(Y\_{0}\) 的预测区间要 短. 这是因为 \(Y\_{0}=a+b x\_{0}+\\varepsilon\_{0}\) 比 \(\\mu\\left(x\_{0}\\right)=a+b x\_{0}\) 多了一项 \(\\varepsilon\_{0}\) 的缘故.
可化为一元线性回归的例子
以上讨论了一元线性回归问题,在实际中常会遇到更为复杂的回归问题,但 在某些情况下,可以通过适当的变量变换,可以将它化成一元线性回归来处理. 下面介绍几种常见的可转化为一元线性回归的模型.
\(Y=\\alpha \\mathrm{e}^{\\beta x} \\cdot \\varepsilon, \\quad \\ln \\varepsilon \\sim N\\left(0, \\sigma^{2}\\right)\)
其中 \(\\alpha, \\beta, \\sigma^{2}\) 是与 \(x\) 无关的未知参数.
将 \(Y=\\alpha \\mathrm{e}^{-\\beta x} \\cdot \\varepsilon\) 两边取对数,得\(\\ln Y=\\ln \\alpha+\\beta x+\\ln \\varepsilon\) 令 \(\\ln Y=Y^{\\prime}, \\ln \\alpha=a, \\beta=b, x=x^{\\prime}, \\ln \\varepsilon=\\varepsilon^{\\prime},\) 上面的对数式可转化为一元线性回归模型:\(Y^{\\prime}=a+b x^{\\prime}+\\varepsilon^{\\prime}, \\quad \\varepsilon^{\\prime} \\sim N\\left(0, \\sigma^{2}\\right)\)
\(Y=\\alpha x^{\\beta} \\cdot \\varepsilon, \\quad \\ln \\varepsilon \\sim N\\left(0, \\sigma^{2}\\right)\)
其中 \(\\alpha, \\beta, \\sigma^{2}\) 是与 \(x\) 无关的未知参数.
将 \(Y=\\alpha x^{\\beta} \\cdot \\varepsilon\) 两边取对数,得\(\\ln Y=\\ln \\alpha+\\beta \\ln x+\\ln \\varepsilon\) 令 \(\\ln Y=Y^{\\prime}, \\ln \\alpha=a, \\beta=b, \\ln x=x^{\\prime}, \\ln \\varepsilon=\\varepsilon^{\\prime},\) 上面的对数式可转化为一元线性回归模型:\(Y^{\\prime}=a+b x^{\\prime}+\\varepsilon^{\\prime}, \\quad \\varepsilon^{\\prime} \\sim N\\left(0, \\sigma^{2}\\right)\)
\(Y=\\alpha+\\beta h(x)+\\varepsilon, \\quad \\varepsilon \\sim N\\left(0, \\sigma^{2}\\right)\)
其中 \(\\alpha, \\beta, \\sigma^{2}\) 是与 \(x\) 无关的未知参数. \(h(x)\) 是 \(x\) 的已知函数 \(,\) 令 \(\\alpha=a, \\beta=b, h(x)\) \(=x^{\\prime},\) 可转化为一元线性回归模型:\(Y=a+b x^{\\prime}+\\varepsilon, \\quad \\varepsilon \\sim N\\left(0, \\sigma^{2}\\right)\)
若在原模型下,例如在原模型 下,对于 \((x, Y)\) 有样本 \(\\left(x\_{1}, y\_{1}\\right),\\left(x\_{2},\\right.\) \(\\left.y\_{2}\\right), \\cdots,\\left(x\_{n}, y\_{n}\\right)\) 就相当于在新模型下有样本 \(\\left(x\_{1}^{\\prime}, y\_{1}\\right),\\left(x\_{2}^{\\prime}, y\_{2}\\right), \\cdots,\\left(x\_{n}^{\\prime},\\right.\)\(\\left.y\_{n}\\right),\) 其中 \(x\_{i}^{\\prime}=h\\left(x\_{i}\\right) .\) 于是就能利用上节的方法来估计 \(a, b\) 或对 \(b\) 作假设检验,或对 \(Y\) 进行预测. 在得到 \(Y\) 关于 \(x^{\\prime}\) 的回归方程后,再将原自变量 \(x\) 代回,就得到\(Y\) 关于 \(x\) 的回归方程,它的图形是一条曲线,也称为曲线回归方程.
之前所讨论的一元线性回归模型是\(Y=a+b x+\\varepsilon, \\quad \\varepsilon \\sim N\\left(0, \\sigma^{2}\\right)\)。 一般情况,一元回归模型为\(Y=\\mu\\left(x ; \\theta\_{1}, \\theta\_{2}, \\cdots, \\theta\_{p}\\right)+\\varepsilon, \\quad \\varepsilon \\sim N\\left(0, \\sigma^{2}\\right)\),其中 \(\\theta\_{1}, \\theta\_{2}, \\cdots, \\theta\_{p}, \\sigma^{2}\) 是与 \(x\) 无关的未知参数.
如果回归函数 \(\\mu\\left(x ; \\theta\_{1}, \\theta\_{2}, \\cdots, \\theta\_{p}\\right)\) 是参数 \(\\theta\_{1}, \\theta\_{2}, \\cdots, \\theta\_{p}\) 的线性函数 \((\) 不必是 \(x\)的线性函数 \()\),则称该一元回归模型为线性回归模型; 若 \(\\mu\\left(x ; \\theta\_{1}, \\theta\_{2}, \\cdots, \\theta\_{p}\\right)\) 是 \(\\theta\_{1}, \\theta\_{2}, \\cdots, \\theta\_{p}\)的非线性函数,则称为非线性回归模型.
上面提到的模型\(Y=\\alpha+\\beta h(x)+\\varepsilon, \\quad \\varepsilon \\sim N\\left(0, \\sigma^{2}\\right)\)是线性回归模型, 而模型\(Y=\\alpha \\mathrm{e}^{\\beta x} \\cdot \\varepsilon, \\quad \\ln \\varepsilon \\sim N\\left(0, \\sigma^{2}\\right)\)以及\(Y=\\alpha x^{\\beta} \\cdot \\varepsilon, \\quad \\ln \\varepsilon \\sim N\\left(0, \\sigma^{2}\\right)\)都不是线性回归模型,但是它们都能经过变量变换转化为线 性回归模型. 又如\(Y=\\theta\_{1} \\mathrm{e}^{\\theta\_{2} x}+\\varepsilon, \\quad \\varepsilon \\sim N\\left(0, \\sigma^{2}\\right)\)它是非线性回归模型. 它不能经过变量变换将它转化为线性回归模型,称为本 质的非线性回归模型, 又如\(Y=\\left(\\theta\_{1}+\\theta\_{2} x+\\theta\_{3} x^{2}\\right)^{-1}+\\varepsilon \\quad(\) Holliday 模型 \(),\) 又如\(Y=\\frac{\\theta\_{1}}{1+\\exp \\left(\\theta\_{2}-\\theta\_{3}^{x}\\right)}+\\varepsilon \\quad(\) Logistic 模型 \(),\) 都是本质的非线性回归模型. 非线性回归模型的解法参见《近代非线性回归分析》(韦博成,南京 : 东南大学出版社,1989).
多元线性回归
在实际问题中,随机变量 \(Y\) 往往与多个普通变量 \(x\_{1}, x\_{2}, \\cdots, x\_{p} \\quad(p\>1)\) 有关. 对于自变量 \(x\_{1}, x\_{2}, \\cdots, x\_{p}\) 的一组确定的值,Y有它的分布. 若 \(Y\) 的数学期望存在,则它是 \(x\_{1}, x\_{2}, \\cdots, x\_{p}\) 的函数,记为 \(\\mu\_{Y \\mid x\_{1}}, x\_{2}, \\cdots, x\_{p}\) 或 \(\\mu\\left(x\_{1}, x\_{2}, \\cdots, x\_{p}\\right),\) 它就是 \(Y\) 关于 \(x\) 的回归函数. 我们感兴趣的是 \(\\mu\\left(x\_{1}, x\_{2}, \\cdots, x\_{p}\\right)\) 是 \(x\_{1}, x\_{2}, \\cdots, x\_{p}\) 的线性函 数的情况.
在这里,仅讨论下述多元线性回归模型 :\(Y=b\_{0}+b\_{1} x\_{1}+\\cdots+b\_{p} x\_{p}+\\varepsilon, \\varepsilon \\sim N\\left(0, \\sigma^{2}\\right)\) 其中 \(b\_{0}, b\_{1}, \\cdots, b\_{p}, \\sigma^{2}\) 都是与 \(x\_{1}, x\_{2}, \\cdots, x\_{p}\) 无关的未知参数.
设\(\\left(x\_{11}, x\_{12}, \\cdots, x\_{1 p}, y\_{1}\\right), \\cdots,\\left(x\_{n 1}, x\_{n 2}, \\cdots, x\_{n p}, y\_{n}\\right)\)是一个样本.
和一元线性回归的情况一样,我们用最大似然估计法来估计参数. 即取 \(\\hat{b}_{0}, \\hat{b}_{1}, \\cdots, \\hat{b}_{p}\) 使当 \(b_{0}=\\hat{b}_{0}, b_{1}=\\hat{b}_{1}, \\cdots, b_{p}=\\hat{b}_{p}\) 时\(Q=\\sum_{i=1}^{n}\\left(y\_{i}-b\_{0}-b\_{1} x\_{i 1}-\\cdots-b\_{p} x\_{i p}\\right)^{2}\)达到最小.
求 \(Q\) 分别关于 \(b\_{0}, b\_{1}, \\cdots, b\_{p}\) 的偏导数,并令它们等于实,得: \(\\left.\\begin{array}{r}\\frac{\\partial Q}{\\partial b\_{0}}=-2 \\sum\_{i=1}^{n}\\left(y\_{i}-b\_{0}-b\_{1} x\_{i 1}-\\cdots-b\_{p} x\_{i p}\\right)=0, \\ \\frac{\\partial Q}{\\partial b\_{j}}=-2 \\sum\_{i=1}^{n}\\left(y\_{i}-b\_{0}-b\_{1} x\_{i 1}-\\cdots-b\_{p} x\_{i j}\\right) x\_{i j}=0, \\ j=1,2, \\cdots, p .\\end{array}\\right}\)
化简得: \(\\left.\\begin{array}{l}b\_{0} n+b\_{1} \\sum\_{i=1}^{n} x\_{i 1}+b\_{2} \\sum\_{i=1}^{n} x\_{i 2}+\\cdots+b\_{p} \\sum\_{i=1}^{n} x\_{i p}=\\sum\_{i=1}^{n} y\_{i} \\ b\_{0} \\sum\_{i=1}^{n} x\_{i 1}+b\_{1} \\sum\_{i=1}^{n} x\_{i 1}^{2}+b\_{2} \\sum\_{i=1}^{n} x\_{i 1} x\_{i 2}+\\cdots+b\_{p} \\sum\_{i=1}^{n} x\_{i 1} x\_{i p}=\\sum\_{i=1}^{n} x\_{i 1} y\_{i} \\ \\vdots \\ b\_{0} \\sum\_{i=1}^{n} x\_{i p}+b\_{1} \\sum\_{i=1}^{n} x\_{i\_{i}} x\_{i 1}+b\_{2} \\sum\_{i=1}^{n} x\_{i p} x\_{i 2}+\\cdots+b\_{p} \\sum\_{i=1}^{n} x\_{i\_{p}}^{2}=\\sum\_{i=1}^{n} x\_{i p} y\_{i} .\\end{array}\\right}\) 称为正规方程组. 为了求解的方便,常要将上方程组写成矩阵的形式.
为此,引入矩阵: \(\\boldsymbol{X}=\\left(\\begin{array}{ccccc}1 \& x\_{11} \& x\_{12} \& \\cdots \& x\_{1 p} \\ 1 \& x\_{2 i} \& x\_{22} \& \\cdots \& x\_{2 p} \\ \\vdots \& \\vdots \& \\vdots \& \& \\vdots \\ 1 \& x\_{n 1} \& x\_{n 2} \& \\cdots \& x\_{n p}\\end{array}\\right), \\boldsymbol{Y}=\\left\[\\begin{array}{c}y\_{1} \\ y\_{2} \\ \\vdots \\ y\_{n}\\end{array}\\right), \\boldsymbol{B}=\\left(\\begin{array}{c}b\_{0} \\ b\_{1} \\ \\vdots \\ b\_{p}\\end{array}\\right) .\)
而有: \(\\boldsymbol{X}^{\\mathrm{T}} \\boldsymbol{X}=\\left(\\begin{array}{cccc}1 \& 1 \& \\cdots \& 1 \\ x\_{11} \& x\_{21} \& \\cdots \& x\_{n 1} \\ \\vdots \& \\vdots \& \& \\vdots \\ x\_{1 p} \& x\_{2 p} \& \\cdots \& x\_{n p}\\end{array}\\right)\\left(\\begin{array}{ccccc}1 \& x\_{11} \& x\_{12} \& \\cdots \& x\_{1 p} \\ 1 \& x\_{21} \& x\_{22} \& \\cdots \& x\_{2 p} \\ \\vdots \& \\vdots \& \\vdots \& \& \\vdots \\ 1 \& x\_{n 1} \& x\_{n 2} \& \\cdots \& x\_{n p}\\end{array}\\right)\) \(=\\left(\\begin{array}{cccc}n \& \\sum\_{i=1}^{n} x\_{i 1} \& \\cdots \& \\sum\_{i=1}^{n} x\_{i p} \\ \\sum\_{i=1}^{n} x\_{i 1} \& \\sum\_{i=1}^{n} x\_{i 1}^{2} \& \\cdots \& \\sum\_{i=1}^{n} x\_{i 1} x\_{i p} \\ \\vdots \& \\vdots \& \& \\vdots \\ \\sum\_{i=1}^{n} x\_{i p} \& \\sum\_{i=1}^{n} x\_{i p} x\_{i 1} \& \\cdots \& \\sum\_{i=1}^{n} x\_{i p}^{2}\\end{array}\\right),\)
\(\\boldsymbol{X}^{\\mathrm{T}} \\boldsymbol{Y}=\\left(\\begin{array}{cccc}1 \& 1 \& \\cdots \& 1 \\ x\_{11} \& x\_{21} \& \\cdots \& x\_{n 1} \\ \\vdots \& \\vdots \& \& \\vdots \\ x\_{1 p} \& x\_{2 p} \& \\cdots \& x\_{n p}\\end{array}\\right)\\left(\\begin{array}{c}y\_{1} \\ y\_{2} \\ \\vdots \\ y\_{n}\\end{array}\\right)=\\left(\\begin{array}{c}\\sum\_{i=1}^{n} y\_{i} \\ \\sum\_{i=1}^{n} x\_{i 1} y\_{i} \\ \\vdots \\ \\sum\_{i=1}^{n} x\_{i p} y\_{i}\\end{array}\\right) .\)
于是正规方程组可以写成: \(\\boldsymbol{X}^{\\mathrm{T}} \\boldsymbol{X B}=\\boldsymbol{X}^{\\mathrm{T}} \\boldsymbol{Y}\)
上式两边左乘 \(\\boldsymbol{X}^{\\mathrm{T}} \\boldsymbol{X}\) 的逆矩阵 \(\\left(\\boldsymbol{X}^{\\mathrm{T}} \\boldsymbol{X}\\right)^{-1}\) (设\(\\left(\\boldsymbol{X}^{\\mathrm{T}} \\boldsymbol{X}\\right)^{-1}\) 存在 \()\) 解得: \(\\hat{\\boldsymbol{B}}=\\left(\\begin{array}{c}\\hat{b}_{0} \\ \\hat{b}_{1} \\ \\vdots \\ \\hat{b}_{p}\\end{array}\\right)=\\left(\\boldsymbol{X}^{\\mathrm{T}} \\boldsymbol{X}\\right)^{-1} \\mathbf{X}^{\\mathrm{T}} \\boldsymbol{Y}\) 这就是我们需要求的 \(\\left(b_{0}, b\_{1}, \\cdots, b\_{p}\\right)^{\\mathrm{T}}\) 的最大似然估计.
我们取\(\\hat{b}_{0}+\\hat{b}_{1} x\_{1}+\\cdots+\\hat{b}_{p} x_{p} \\stackrel{\\text { 记成 }}{=}\\hat{y}\)作为 \(\\mu\\left(x\_{1}, x\_{2}, \\cdots, x\_{p}\\right)=b\_{0}+b\_{1} x\_{1}+\\cdots+b\_{p} x\_{p}\) 的估计. 方程\(\\hat{y}=\\hat{b}_{0}+\\hat{b}_{1} x\_{1}+\\cdots+\\hat{b}_{p} x_{p}\)称为 \(p\) 元经验线性回归方程,简称回归方程.
例子 下面给出了某种产品每件平均单价 \(Y\) (元) 与批量 \(x\) (件) 之间的关系的一组数据:
画出散点图:
我们选取模型\(Y=b\_{0}+b\_{1} x+b\_{2} x^{2}+\\varepsilon, \\varepsilon \\sim N\\left(0, \\sigma^{2}\\right)\)来拟合它。
现在来求它的回归方程: 令 \(x\_{1}=x, x\_{2}=x^{2}\),则模型可以写成\(Y=b\_{0}+b\_{1} x\_{1}+b\_{2} x\_{2}+\\varepsilon, \\quad \\varepsilon \\sim N\\left(0, \\sigma^{2}\\right)\), 这是一个二元线性回归模型。 现在有: \(\\boldsymbol{X}=\\left(\\begin{array}{lll}1 \& 20 \& 400 \\ 1 \& 25 \& 625 \\ 1 \& 30 \& 900 \\ 1 \& 35 \& 1 \& 225 \\ 1 \& 40 \& 1 \& 600 \\ 1 \& 50 \& 2 \& 500 \\ 1 \& 60 \& 3 \& 600 \\ 1 \& 65 \& 4 \& 225 \\ 1 \& 70 \& 4 \& 900 \\ 1 \& 75 \& 5 \& 625 \\ 1 \& 80 \& 6 \& 400 \\ 1 \& 90 \& 8 \& 100\\end{array}\\right), \\boldsymbol{Y}=\\left(\\begin{array}{l}1.81 \\ 1.70 \\ 1.65 \\ 1.55 \\ 1.48 \\ 1.40 \\ 1.30 \\ 1.26 \\ 1.24 \\ 1.21 \\ 1.20 \\ 1.18\\end{array}\\right), \\boldsymbol{B}=\\left\[\\begin{array}{l}b\_{0} \\ b\_{1} \\ b\_{2}\\end{array}\\right) .\) 经计算: \(\\boldsymbol{X}^{\\mathrm{T}} \\boldsymbol{X}=\\left(\\begin{array}{ccc}12 \& 640 \& 40100 \\ 640 \& 40100 \& 2779000 \\ 40100 \& 2779000 \& 204 702 500\\end{array}\\right)\)
\(\\Delta=1.41918 \\times 10^{11}\), 得正规方程组的解: \(\\hat{\\boldsymbol{B}}=\\left(\\begin{array}{l}\\hat{b}_{0} \\ \\hat{b}_{1} \\ \\hat{b}\_{2}\\end{array}\\right)=\\left(\\boldsymbol{X}^{\\mathrm{T}} \\boldsymbol{X}\\right)^{-1} \\boldsymbol{X}^{\\mathrm{T}} \\boldsymbol{Y}=\\left(\\boldsymbol{X}^{\\mathrm{T}} \\boldsymbol{X}\\right)^{-1} \\quad\\left(\\begin{array}{l}16.98 \\ 851.3 \\ 51162\\end{array}\\right)\) \(=\\left(\\begin{array}{lll}2.198 266 29 \\ -0.022 522 36 \\ 0.000 125 07\\end{array}\\right)\) 于是得到回归方程为\(\\hat{y}=2.19826629-0.02252236 x+0.00012507 x^{2} .\)
像一元线性回归一样,多元线性回归模型\(Y=b\_{0}+b\_{1} x\_{1}+\\cdots+b\_{p} x\_{p}+\\varepsilon, \\varepsilon \\sim N\\left(0, \\sigma^{2}\\right)\)往往是一种假定,为了考察这一假定是否符合实际观察结果,还需进行以下的假设检验 : \(H\_{0}: \\quad b\_{1}=b\_{2}=\\cdots=b\_{p}=0\) \(\\mathrm{H}_{1}: b_{i}\) 不全为零 若在显著性水平 \(\\alpha\) 下拒绝 \(H\_{0} .\) 我们就认为回归效果是显著的.
另外,也与一元线性回归一样,多元线性回归方程的一个重要应用是确定给定点 \(\\left(x\_{01}, x\_{02}, \\cdots, x\_{0 p}\\right)\) 处对应的 \(Y\) 的观察值的预测区间.
最后我们指出,在实际问题中,与Y有关的因素往往很多,如果将它们都取作自变量必然会导致所得到的回归方程很庞大。 实际上,有些自变量对Y的影响很小,如果将这些自变量剔除,不但能使回归方程较为简洁,便于应用,且能明确哪些因素(即自变量)的改变对Y有显著的影响,从而使人们对事物有进一步的认识。 通常可用逐步回归法达到这一目的。 上述关于模型的线性假设的检验、观察值的预测区间、逐步回归等内容,读者可参阅华东师范大学出版社出版的《回归分析及其试验设计》一书
在实际中,需要考虑的影响Y的因素较多,即自变量的个数较多。因此要求解一个多元线性回归的问题,计算工作量是相当大的,这就需要借助于计算机来进行计算。
发表回复