Contents
- 1 概率论与数理统计-数理统计-基本概念
- 1.1 总体与样本
- 1.2 总体分布的粗略了解-直方图和箱线图
- 1.3 抽样分布
- 1.3.1 统计量
- 1.3.1.1 统计量定义:无参样本函数
- 1.3.1.2 常用统计量
- 1.3.1.3 样本矩与统计量的性质
- 1.3.1.3.1 若总体的k阶矩\(\\mu\_k=E(X^k)\)存在,当\(n\\rightarrow\\infty\)时,样本的k阶矩\(\\frac{1}{n} \\sum\_{i=1}^{n} X\_{i}^{k}\) \(\\stackrel{P}{\\longrightarrow}\)总体的k阶矩\(\\mu\_k=E(X^k)\)
- 1.3.1.3.2 样本矩的函数依概率收敛于总体矩的函数\(g\\left(A\_{1}, A\_{2}, \\cdots, A\_{k}\\right) \\stackrel{P}{\\longrightarrow} g\\left(\\mu\_{1}, \\mu\_{2}, \\cdots, \\mu\_{k}\\right)\)
- 1.3.2 经验分布函数:总体分布的进一步了解
- 1.3.3 常用统计量的分布
- 1.3.1 统计量
概率论与数理统计-数理统计-基本概念
前面章节讲述了概率论的基本内容,随后将讲述数理统计。
数理统计以概率论为理论基础,根据试验或观察得到的数据,来研究随机现象,对研究对象的客观规律性作出种种合理的估计和判断。
数理统计的内容包括:
- 如何收集、整理数据资料[^1](数据资料指所研究对象的某数据指标的观测值,即随机变量的观测值)
- 如何对所得的数据资料进行分析、研究,从而对所研究的对象的性质、特点作出推断(统计推断)。
概率论与数理统计的对比:
在概率论中,我们所研究的随机变量,它的分布都是假设已知的,在这一前提下去研究它的性质、特点和规律性,例如求出它的数字特征,讨论随机变量函数的分布,介绍常用的各种分布等。 在数理统计中,我们研究的随机变量,它的分布是未知的,或者是不完全知道的,人们是通过对所研究的随机变量进行重复独立的观察,得到许多观察值,对这些数据进行分析,从而对所研究的随机变量的分布作出种种推断的。
本章我们介绍总体、随机样本及统计量等基本概念,并着重介绍几个常用统计量及抽样分布。
总体与样本
总体的概念
我们知道,随机试验的结果很多是可以用数来表示的,另有一些试验的结果虽是定性的,但总可以将它数量化。
例如
例如,检验某个学校学生的血型这一试验,其可能结果有O型、A型、B型、AB型4种,是定性的。如果分别以1,2,3,4依次记这4种血型,那么试验的结果就能用数来表示了。
研究对象的总体,简称为总体。 而在数理统计中,我们往往关心研究对象的某一项数量指标(即随机变量,例如研究某种型号灯泡的寿命这一数量指标),考虑与这一数量指标相联系的随机试验,对这一数量指标进行试验或观察,我们将试验的全部可能的观察值称为总体[^2],这些值不一定都不相同,数目上也不一定是有限的,每一个可能观察值称为个体。 总体中所包含的个体的个数称为总体的容量。容量为有限的称为有限总体,容量为无限的称为无限总体。
[^2]: 注意区分数理统计中的总体与概率论中的样本空间的概念。样本空间与总体有何区别? – robot DDD的回答 – 知乎 https://www.zhihu.com/question/300729716/answer/522207094
总体中的每一个个体是随机试验的一个观察值,因此它是某一随机变量X的值,这样,一个总体对应于一个随机变量X.我们对总体的研究就是对一个随机变量X的研究,X的分布函数和数字特征就称为总体的分布函数和数字特征,今后将不区分总体与相应的随机变量,笼统称为总体X
样本的概念
样本的引入
在实际中,总体的分布一般是未知的,或只知道它具有某种形式而其中包含着未知参数。 在数理统计中,人们都是通过从总体中抽取一部分个体,根据获得的数据来对总体分布作出推断的。被抽出的部分个体叫做总体的一个样本。
所谓从总体抽取一个个体,就是对总体X进行一次观察并记录其结果。 我们在相同的条件下对总体X,进行n次重复的、独立的观察,将n次观察结果按试验的次序记为\(X\_{1}, X\_{2}, \\cdots, X\_{n}\)。 由于\(X\_{1}, X\_{2}, \\cdots, X\_{n}\)是都随机变量X的观察结果,且每次观察都是在相同条件下进行的,有理由认为\(X\_{1}, X\_{2}, \\cdots, X\_{n}\)都是与X同分布的随机变量。 由于\(X\_{1}, X\_{2}, \\cdots, X\_{n}\)是都随机变量X的观察结果,且每次观察都是独立进行的,则\(X\_{1}, X\_{2}, \\cdots, X\_{n}\)作为随机变量是相互独立的。 这样获取的互相独立的、与X同分布的\(X\_{1}, X\_{2}, \\cdots, X\_{n}\),称为来自总体的一个简单随机样本。
当 \(n\) 次观察一经完成,我们就得到一组实数 \(x\_{1}, x\_{2}, \\cdots, x\_{n},\) 它们依次是随机 变量 \(X\_{1}, X\_{2}, \\cdots, X\_{n}\) 的观察值,称为样本值.
对于有限总体,采用放回抽样(独立重复试验)就能得到简单随机样本,但放回抽样使用起来不方便,当个体的总数N比要得到的样本的容量n大得多时,在实际中可将不放回抽样近似地当作放回抽样来处理。 至于无限总体,因抽取一个个体不影响它的分布,所以总是用不放回抽样例如,在生产过程中,每隔一定时间抽取一个个体,抽取n个就得到一个简单随机样本,实验室中的记录,水文、气象等观察资料都是样本。试制新产品得到的样品的质量指标,也常被认为是样本
样本的定义
设 \(X\) 是具有分布函数 \(F\) 的随机变量,若 \(X\_{1}, X\_{2}, \\cdots, X\_{n}\) 是具有同一分布函数 \(F\) 的、相互独立的随机变量,则称 \(X\_{1}, X\_{2}, \\cdots, X\_{n}\) 为从分布函数 \(F\) ( 或总体F、或总体X)得到的容量为n的简单随机样本,简称样本,它们的观察值\(x\_{1}, x\_{2}, \\cdots, x\_{n}\) 称为样本值,又称为 \(X\) 的 \(n\) 个独立的观察值.
可以将样本看成一个随机向量,写成\(\\left(X\_{1}, X\_{2}, \\cdots, X\_{n}\\right)\),此时样本值可以写成\(\\left(x\_{1}, x\_{2}, \\cdots, x\_{n}\\right)\)。 若\(\\left(x\_{1}, x\_{2}, \\cdots, x\_{n}\\right)\)和\(\\left(y\_{1}, y\_{2}, \\cdots, y\_{n}\\right)\)都是相应于样本\(\\left(X\_{1}, X\_{2}, \\cdots, X\_{n}\\right)\)的样本值,一般来说它们是不相同的。
若\(\\left(X\_{1}, X\_{2}, \\cdots, X\_{n}\\right)\)是F的一个样本,则\(\\left(X\_{1}, X\_{2}, \\cdots, X\_{n}\\right)\)相互独立,且它们的分布函数都是F, 所以\(\\left(X\_{1}, X\_{2}, \\cdots, X\_{n}\\right)\)的分布函数为\(F^{*}\\left(x\_{1}, x\_{2}, \\cdots, x\_{n}\\right)=\\prod\_{i=1}^{n} F\\left(x\_{i}\\right)\), 又若X具有概率密度函数\(f\),则\(\\left(X\_{1}, X\_{2}, \\cdots, X\_{n}\\right)\)的概率密度为\(f^{*}\\left(x\_{1}, x\_{2}, \\cdots, x\_{n}\\right)=\\prod\_{i=1}^{n} f\\left(x\_{i}\\right)\)
总体分布的粗略了解-直方图和箱线图
为了研究总体分布的性质,人们通过试验得到许多观察值,一般来说这些数值是杂乱无章的。 为了利用这些观察值进行统计分析,需要将这些数据进行整理,还常常借助表格或图形来加以描述。 通过对连续型随机变量X引入“频率直方图”,然后介绍“箱线图”,可以使人们对总体的分布有一个粗略的了解。
频率直方图
比如要考察伊特拉斯坎人头颅的大小(总体),抽取/调查84个伊特拉斯坎人头颅大小数据(样本),作为样本: \(\\begin{array}{llllllllll}141 \& 148 \& 132 \& 138 \& 154 \& 142 \& 150 \& 146 \& 155 \& 158 \\ 150 \& 140 \& 147 \& 148 \& 144 \& 150 \& 149 \& 145 \& 149 \& 158 \\ 143 \& 141 \& 144 \& 144 \& 126 \& 140 \& 144 \& 142 \& 141 \& 140 \\ 145 \& 135 \& 147 \& 146 \& 141 \& 136 \& 140 \& 146 \& 142 \& 137 \\ 148 \& 154 \& 137 \& 139 \& 143 \& 140 \& 131 \& 143 \& 141 \& 149 \\ 148 \& 135 \& 148 \& 152 \& 143 \& 144 \& 141 \& 143 \& 147 \& 146 \\ 150 \& 132 \& 142 \& 142 \& 143 \& 153 \& 149 \& 146 \& 149 \& 138 \\ 142 \& 149 \& 142 \& 137 \& 134 \& 144 \& 146 \& 147 \& 140 \& 142 \\ 140 \& 137 \& 152 \& 145 \& \& \& \& \& \& \\end{array}\)
样本看起来比较杂乱,需要先进行整理(作频数/频率分布表): 根据最大最小值划分成几个区间,每个区间组距\(\\Delta\).

根据频数分布表作频率分布直方图:
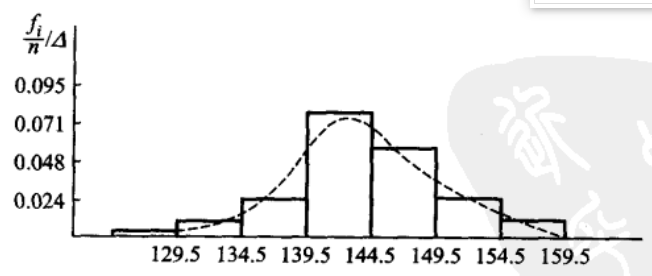
其中\(f\_i\)是在对应区间内的频数,n是总体的大小,\(\\Delta\)是区间大小。
箱线图
样本p分位数
设有容量为n的样本观察值\(x\_{1}, x\_{2}, \\cdots, x\_{n}\),样本的p分位数(0<p<1)记为\(x\_p\), \(x\_p\)具有如下性质: 1)至少有np个数小于等于\(x\_p\), 2)至少有n(1-p)个数大于等于\(x\_p\)
\(x\_{p}=\\left{\\begin{array}{ll}x\_{(\[n p\]+1)}, \& \\text { 当 } n p \\text { 不是整数 } \\ \\frac{1}{2}\\left\[x\_{(n p)}+x\_{(n p+1)}\\right\], \& \\text { 当 } n p \\text { 是整数. }\\end{array}\\right.\)
0.25 分位数 \(x\_{0.25}\) 称为第一四分位数,又记为 \(Q\_{1} ; 0.75\) 分位数 \(x\_{0.75}\) 称为第三四分位数,又记为 \(Q\_{3}\). $ x_{0.25}, x_{0.5}, x_{0.75}$ 在统计中是很有用的.
箱线图的组成
数据集的箱线图是由箱子和直线组成的图形,它是基于以下 5 个数的图形 概括 : 最小值 Min, 第一四分位数 \(Q\_{1}\), 中位数 \(M,\) 第三四分位数 \(Q\_{3}\) 和最大值 Max.
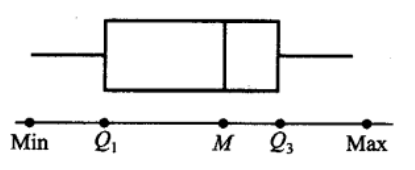
从箱线图上可以看出数据集的如下特征: 1)中心位置(M点), 2)散布程度(各区间中数据各占1/4,区间越短数据越集中), 3)对称性
箱线图特别适合比较两个数据集之间的性质,为此可以将几个数据集的数据画在同一个数轴上。
若如下表示男生和女生肺活量数据,则可以明显看出男生的肺活量比女生的大。 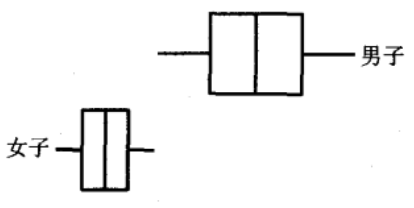
修正箱线图
在数据集中某一个观察值不寻常地大于或小于该数集中的其他数据,称为疑似异常值。疑似异常值的存在,会对随后的计算结果产生不适当的影响检查疑似异常值并加以适当的处理是十分重要的。箱线图只要稍加修改,就能用来检测数据集是否存在疑似异常值。
第一四分位数 \(Q\_{1}\) 与第三四分位数 \(Q\_{3}\) 之间的距离 \(: Q\_{3}-Q\_{1} \\stackrel{\\text { 记为 }}{=}I Q R\) ,称为四分位数间距. 若数据小于 \(Q\_{1}-1.5 I Q R\) 或大于 \(Q\_{3}+1.5 I Q R\),就认为它是疑似异常值.
画箱线图时,将疑似异常值用*号在图上对应位置单独画出,用排除疑似异常值后的数据集画箱线图。
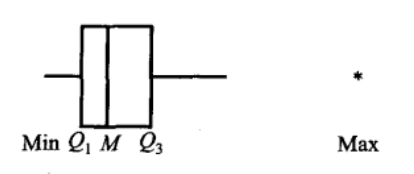
疑似异常值的来源: (1)数据的测量、记录或输入计算机时的错误; (2)数据来自不同的总体; (3)数据是正确的,但它只体现小概率事件。
当检测出疑似异常值时,人们需对疑似异常值出现的原因加以分析。如果是由于测量或记录的错误,或某些其他明显的原因造成的,将这些疑似异常值从数据集中丢弃就可以了。
用中位数来描述数据集的中心趋势,而不用平均值,也是因为后者受疑似异常值的影响较大。
抽样分布
样本是进行统计推断的依据。在应用时,往往不是直接使用样本本身,而是针对不同的问题构造样本的适当函数,利用这些样本的函数进行统计推断。
统计量
统计量定义:无参样本函数
设 \(X\_{1}, X\_{2}, \\cdots, X\_{n}\) 是来自总体 \(X\) 的一个样本 \(, g\\left(X\_{1}, X\_{2}, \\cdots, X\_{n}\\right)\) 是 \(X\_{1},\)\(X\_{2}, \\cdots, X\_{n}\) 的函数,若 \(g\) 中不含未知参数 \(,\) 则称 \(g\\left(X\_{1}, X\_{2}, \\cdots, X\_{n}\\right)\) 是一统计量.
因为 \(X\_{1}, X\_{2}, \\cdots, X\_{n}\) 都是随机变量,而统计量 \(g\\left(X\_{1}, X\_{2}, \\cdots, X\_{n}\\right)\) 是随机变量的函数,因此统计量是一个随机变量. 设 \(x\_{1}, x\_{2}, \\cdots, x\_{n}\) 是相应于样本 \(X\_{1}, X\_{2}, \\cdots,\) \(X\_{n}\) 的样本值,则称 \(g\\left(x\_{1}, x\_{2}, \\cdots, x\_{n}\\right)\) 是 \(g\\left(X\_{1}, X\_{2}, \\cdots, X\_{n}\\right)\) 的观察值(统计量的观察值).
常用统计量
设 \(X\_{1}, X\_{2}, \\cdots, X\_{n}\) 是来自总体 \(X\) 的一个样本,\(x\_{1}, x\_{2}, \\cdots, x\_{n}\) 是这一样本的观察值.
样本均值
\(\\bar{X}=\\frac{1}{n} \\sum\_{i=1}^{n} X\_{i}\)
样本方差[^3]
\(S^{2}=\\frac{1}{n-1} \\sum\_{i=1}^{n}\\left(X\_{i}-\\bar{X}\\right)^{2}=\\frac{1}{n-1}\\left(\\sum\_{i=1}^{n} X\_{i}^{2}-n \\bar{X}^{2}\\right)\)
注意区分:样本方差、随机变量的方差(总体的方差)、样本的二阶中心矩 样本\(X\_1,\\cdots,X\_n\)的方差\(S^{2}=\\frac{1}{n-1} \\sum\_{i=1}^{n}\\left(X\_{i}-\\bar{X}\\right)^{2}\), 样本\(X\_1,\\cdots,X\_n\)的二阶中心矩\(B\_{2}=\\frac{1}{n} \\sum\_{i=1}^{n}\\left(X\_{i}-\\bar{X}\\right)^{2}\) 随机变量X的方差(总体的方差)\(D(X)=E\\left\[X-E(X)\\right\]^2\), 随机变量X的方差同时也是随机变量X的二阶中心矩。 若X是离散型随机变量,方差为\(D(X)=\\sum\_{i=1}^{\\infty}\\left\[x\_{i}-E(X)\\right\]^{2} p\\left(x\_{i}\\right)\)
[^3]: 虽然样本\(X\_1,\\cdots,X\_n\)相互独立,但是在计算方差时,\(X\_1,\\cdots,X\_n\)自由度为n-1,因为计算方差是在已知样本均值\(\\bar{X}=\\frac{1}{n} \\sum\_{i=1}^{n} X\_{i}\)的情况下进行的,这也是一条约束。则分配到每个自由度上的概率都是\(\\frac{1}{n-1}\)
样本标准差
\(S=\\sqrt{S^{2}}=\\sqrt{\\frac{1}{n-1} \\sum\_{i=1}^{n}\\left(X\_{i}-\\bar{X}\\right)^{2}}\)
样本k阶(原点)矩
\(A\_{k}=\\frac{1}{n} \\sum\_{i=1}^{n} X\_{i}^{k}, k=1,2, \\cdots\)
样本k阶中心矩
\(B\_{k}=\\frac{1}{n} \\sum\_{i=1}^{n}\\left(X\_{i}-\\bar{X}\\right)^{k}, k=2,3, \\cdots\)
样本均值的观测值
\(\\bar{x}=\\frac{1}{n} \\sum\_{i=1}^{n} x\_{i} ;\)
样本方差的观测值
\(s^{2}=\\frac{1}{n-1} \\sum\_{i=1}^{n}\\left(x\_{i}-\\bar{x}\\right)^{2}=\\frac{1}{n-1}\\left(\\sum\_{i=1}^{n} x\_{i}^{2}-n \\bar{x}^{2}\\right)\)
样本标准差的观测值
\(s=\\sqrt{\\frac{1}{n-1} \\sum\_{i=1}^{n}\\left(x\_{i}-\\bar{x}\\right)^{2}}\)
样本k阶(原点)矩的观测值
\(a\_{k}=\\frac{1}{n} \\sum\_{i=1}^{n} x\_{i}^{k}, \\quad k=1,2, \\cdots ;\)
样本k阶中心矩的观测值
\(b\_{k}=\\frac{1}{n} \\sum\_{i=1}^{n}\\left(x\_{i}-\\bar{x}\\right)^{k}, \\quad k=2,3, \\cdots\)
样本矩与统计量的性质
若总体的k阶矩\(\\mu\_k=E(X^k)\)存在,当\(n\\rightarrow\\infty\)时,样本的k阶矩\(\\frac{1}{n} \\sum\_{i=1}^{n} X\_{i}^{k}\) \(\\stackrel{P}{\\longrightarrow}\)总体的k阶矩\(\\mu\_k=E(X^k)\)
\(X\_{1}, X\_{2}, \\cdots, X\_{n}\) 独立且与 \(X\) 同分布,所以 \(X\_{1}^{k}, X\_{2}^{k}, \\cdots, X\_{n}^{k}\)独立且与 \(X^{k}\) 同分布. 故有\(E\\left(X\_{1}^{k}\\right)=E\\left(X\_{2}^{k}\\right)=\\cdots=E\\left(X\_{n}^{k}\\right)=\\mu\_{k}\) 继而由辛钦大数定律知道\(A\_{k}=\\frac{1}{n} \\sum\_{i=1}^{n} X\_{i}^{k} \\stackrel{P}{\\longrightarrow} \\mu\_{k}, \\quad k=1,2, \\cdots\)
样本矩的函数依概率收敛于总体矩的函数\(g\\left(A\_{1}, A\_{2}, \\cdots, A\_{k}\\right) \\stackrel{P}{\\longrightarrow} g\\left(\\mu\_{1}, \\mu\_{2}, \\cdots, \\mu\_{k}\\right)\)
由上一条性质\(A\_{k}=\\frac{1}{n} \\sum\_{i=1}^{n} X\_{i}^{k} \\stackrel{P}{\\longrightarrow} \\mu\_{k}, \\quad k=1,2, \\cdots\), 再根据依概率收敛的序列的性质, 立即可知\(g\\left(A\_{1}, A\_{2}, \\cdots, A\_{k}\\right) \\stackrel{P}{\\longrightarrow} g\\left(\\mu\_{1}, \\mu\_{2}, \\cdots, \\mu\_{k}\\right)\)
即(当\(n\\rightarrow\\infty\)时)样本各阶矩的函数,依概率收敛于总体相应各阶矩的函数。
这是后面矩估计法的理论依据。
经验分布函数:总体分布的进一步了解
我们还可以作出与总体分布函数 \(F(x)\) 相应的统计量 经验分布函数.
设 \(X\_{1}, X\_{2}, \\cdots, X\_{n}\) 是总体 \(F\) 的一个样本,用S( \(x\) ) \(-\\infty\<x\<\\infty\) 表示 \(X\_{1}, X\_{2}, \\cdots, X\_{n}\) 中不大于 \(x\) 的随机变量的个数. 定义经验分布 函数\(F\_{n}(x)=\\frac{1}{n} S(x),-\\infty\<x\<\\infty\)
例如,设总体 \(F\) 具有一个样本值 \(1,2,3,\) 则经验分布函数 \(F\_{3}(x)\) 的观察值为: \(F\_{3}(x)=\\left{\\begin{array}{ll}0, \& \\text { 若 } x\<1, \\ \\frac{1}{3}, \& \\text { 若 } 1 \\leqslant x\<2, \\ \\frac{2}{3}, \& \\text { 若 } 2 \\leqslant x\<3, \\ 1, \& \\text { 若 } x \\geqslant 3 .\\end{array}\\right.\)
对于经验分布函数 \(F\_{n}(x),\) 格里汶科 (Glivenko)在 1933 年证明了以下的结果 :对于任一实数 \(x,\) 当 \(n \\rightarrow \\infty\) 时 \(F\_{n}(x)\) 以概率 1 一致收敛于分布函数 \(F(x)\), 即\(P\\left{\\lim \_{n \\rightarrow \\infty} \\sup _{-\\infty\<x\<\\infty}\\left|F_{n}(x)-F(x)\\right|=0\\right}=1\)
因此,对于任一实数 \(x\) 当 \(n\) 充分大时,经验分布函数的任一个观察值 \(F\_{n}(x)\) 与总体分布函数 \(F(x)\) 只有微小的差别,从而在实际上可当作 \(F(x)\) 来使用。
这也是样本的频率分布直方图可以粗略了解总体的分布的原因。
常用统计量的分布
统计量的分布称为抽样分布。 在使用统计量进行统计推断时常需知道它的分布。当总体的分布函数已知时,抽样分布是确定的,然而要求出统计量的精确分布,一般来说是困难的。
本节介绍来自正态总体的几个常用统计量的分布:\(\\chi^{2}\) 分布、t分布、\(F\) 分布(统计学三大分布)。 样本均值、样本方差的性质,特别是总体服从正态分布情况下样本均值和方差的性质。
\(\\chi^{2}\)分布
设 \(X\_{1}, X\_{2}, \\cdots, X\_{n}\) 是来自总体 \(N(0,1)\) 的样本,则称统计量\(\\chi^{2}=X\_{1}^{2}+X\_{2}^{2}+\\cdots+X\_{n}^{2}\)服从自由度为 \(n\) 的 \(\\chi^{2}\) 分布,记为 \(\\chi^{2} \\sim \\chi^{2}(n) .\) 此处,自由度是指等式右端包含的独立变量的个数.
可以看出,\(\\chi^{2}\) 是标准正态总体情况下,抽取样本的2阶矩。
\(\\chi^{2}(n)\) 分布的概率密度为\(f(y)=\\left{\\begin{array}{cl}\\frac{1}{2^{n / 2} \\Gamma(n / 2)} y^{n / 2-1} \\mathrm{e}^{-y / 2}, \& y\>0 \\ 0, \& \\text { 其他. }\\end{array}\\right.\)
\(\\chi^{2}(n)\) 分布密度函数的图形:

\(\\chi^{2}\) 分布的性质: 1)\(\\chi^{2}\) 分布可用\(\\Gamma\)分布[^4]表述:\(\\chi^{2}=\\sum\_{i=1}^{n} X\_{i}^{2} \\sim \\Gamma\\left(\\frac{n}{2}, 2\\right)\) 2)\(\\chi^{2}\) 分布的可加性[^5]:设 \(\\chi\_{1}^{2} \\sim \\chi^{2}\\left(n\_{1}\\right), \\chi\_{2}^{2} \\sim \\chi^{2}\\left(n\_{2}\\right),\) 并且 \(\\chi\_{1}^{2}, \\chi\_{2}^{2}\) 相互独立,则有\(\\chi\_{1}^{2}+\\chi\_{2}^{2} \\sim \\chi^{2}\\left(n\_{1}+n\_{2}\\right)\) 3)\(\\chi^{2}\) 分布的数学期望与方差[^6]:若 \(\\chi^{2} \\sim \\chi^{2}(n),\) 则有\(E\\left(\\chi^{2}\\right)=n, \\quad D\\left(\\chi^{2}\\right)=2 n\)
[^4]: 若\(X \\sim \\Gamma(\\alpha, \\theta)\)对应的概率密度函数为\(f\_{X}(x)=\\left{\\begin{array}{ll}\\frac{1}{\\theta^{\\alpha} \\Gamma(\\alpha)} x^{\\alpha-1} \\mathrm{e}^{-x / \\theta}, \& x\>0 \\ 0, \& \\text { 其他 }\\end{array} \\quad \\alpha\>0, \\theta\>0\\right.\)。 [^5]: 可根据如下性质导出:若随机变量X与Y独立,且\(X \\sim \\Gamma(\\alpha, \\theta), Y \\sim \\Gamma(\\beta, \\theta)\),则\(X+Y \\sim \\Gamma(\\alpha+\\beta, \\theta)\) [^6]: 完全可由\(\\chi^{2}\) 的定义+数学期望定义+方差定义导出
\(\\chi^{2}\) 分布的分位点: 对于给定的正数 \(\\alpha, 0\<\\alpha\<1,\) 称满足条件\(P\\left{\\chi^{2}\>\\chi\_{\\alpha}^{2}(n)\\right}=\\int\_{\\chi\_{a}^{2}(n)}^{\\infty} f(y) \\mathrm{d} y=\\alpha\)的点 \(\\chi\_{a}^{2}(n)\) 为 \(\\chi^{2}(n)\) 分布的上 \(\\alpha\) 分位点。

当n比较小(n<40)时,\(\\chi^{2}\) 分布的\(\\alpha\)分位点 \(\\chi\_{a}^{2}(n)\) 的值通过查表获得; 当n比较大时,近似有\(\\chi\_{a}^{2}(n) \\approx \\frac{1}{2}\\left(z\_{\\alpha}+\\sqrt{2 n-1}\\right)^{2}\),其中 \(z\_{a}\) 是标准正态分布的上 \(\\alpha\) 分位点。
t分布
设 \(X \\sim N(0,1), Y \\sim \\chi^{2}(n),\) 且 \(X, Y\) 相互独立,则称随机变量\(t=\\frac{X}{\\sqrt{Y / n}}\)服从自由度为 \(n\) 的 \(t\) 分布. 记为 \(t \\sim t(n)\).\(t\) 分布又称学生氏( Student)分布.
\(t(n)\)分布的概率密度函数:\(h(t)=\\frac{\\Gamma\[(n+1) / 2\]}{\\sqrt{\\pi n} \\Gamma(n / 2)}\\left(1+\\frac{t^{2}}{n}\\right)^{-(n+1) / 2},-\\infty\<t\<\\infty\)
\(t(n)\)分布的概率密度图像:
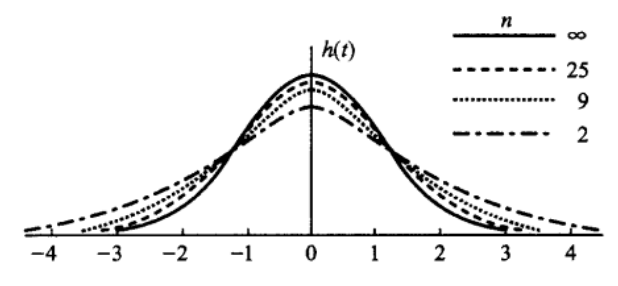
\(t(n)\)分布的性质: 1)概率密度\(h(t)\) 的图形关于 \(t=0\) 对称 2)概率密度\(\\lim \_{n \\rightarrow \\infty} h(t)=\\frac{1}{\\sqrt{2 \\pi}} \\mathrm{e}^{-t^{2} / 2}\),即当 \(n\) 足够大时 \(t\) 分布近似于 \(N\) (0,1)分布。(注意n较小时,与标准正态分布相差较大)
t分布的分位点: 对于给定的 \(\\alpha, 0\<\\alpha\<1\),称满足条件\(P\\left{t\>t\_{\\alpha}(n)\\right}=\\int\_{t\_{\\alpha}(n)}^{\\infty} h(t) \\mathrm{d} t=\\alpha\)的点 \(t\_{\\alpha}(n)\) 为 \(t(n)\) 分布的上 \(\\alpha\) 分位点。 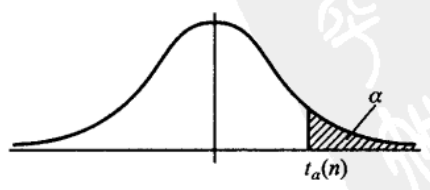 由 \(t\) 分布上 \(\\alpha\) 分位点的定义及概率密度 \(h(t)\) 图形的对称性知\(t\_{1-\\alpha}(n)=-t\_{a}(n)\)。
由 \(t\) 分布上 \(\\alpha\) 分位点的定义及概率密度 \(h(t)\) 图形的对称性知\(t\_{1-\\alpha}(n)=-t\_{a}(n)\)。
当n比较小(n<=45)时,\(t\) 分布的上 \(\\alpha\) 分位点可查表获得; 当n比较大时,\(t\) 分布的上 \(\\alpha\) 分位点可近似为标准正态分布上 \(\\alpha\) 分位点
\(F\) 分布
设 \(U \\sim \\chi^{2}\\left(n\_{1}\\right), V \\sim \\chi^{2}\\left(n\_{2}\\right),\) 且 \(U, V\) 相互独立,则称随机变量\(F=\\frac{U / n\_{1}}{V / n\_{2}}\)服从自由度为 \(\\left(n\_{1}, n\_{2}\\right)\) 的 \(F\) 分布,记为 \(F \\sim F\\left(n\_{1}, n\_{2}\\right)\).
\(F\\left(n\_{1}, n\_{2}\\right)\) 分布的概率密度为\(\\psi(y)=\\left{\\begin{array}{ll}\\frac{\\Gamma\\left\[\\left(n\_{1}+n\_{2}\\right) / 2\\right\]\\left(n\_{1} / n\_{2}\\right)^{n\_{1} / 2} y^{\\left(n\_{1} / 2\\right)-1}}{\\Gamma\\left(n\_{1} / 2\\right) \\Gamma\\left(n\_{2} / 2\\right)\\left\[1+\\left(n\_{1} y / n\_{2}\\right)\\right\]^{\\left(n\_{1}+n\_{2}\\right) / 2}}, \& y\>0 \\ 0, \& \\text { 其他. }\\end{array}\\right.\)
\(F\\left(n\_{1}, n\_{2}\\right)\) 分布的概率密度的图形:
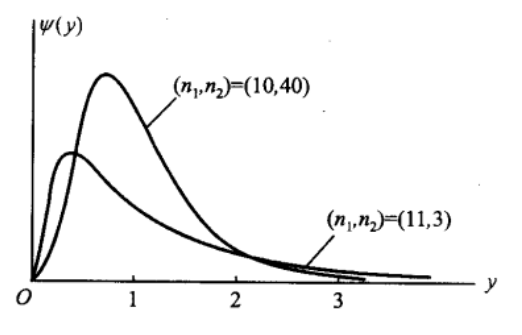
若 \(F \\sim F\\left(n\_{1}, n\_{2}\\right),\) 则\(\\frac{1}{F} \\sim F\\left(n\_{2}, n\_{1}\\right)\)
F分布的分位点:对于给定的 \(\\alpha, 0\<\\alpha\<1,\) 称满足条件\(P\\left{F\>F\_{\\alpha}\\left(n\_{1}, n\_{2}\\right)\\right}=\\int\_{F\_{\\alpha}\\left(n\_{1}, n\_{2}\\right)}^{\\infty} \\psi(y) \\mathrm{d} y=\\alpha\)的点 \(F\_{\\alpha}\\left(n\_{1}, n\_{2}\\right)\) 为 \(F\\left(n\_{1}, n\_{2}\\right)\) 分布的上 \(\\alpha\) 分位点

F分布的分位点性质:\(F\_{1-\\alpha}\\left(n\_{1}, n\_{2}\\right)=\\frac{1}{F\_{\\alpha}\\left(n\_{2}, n\_{1}\\right)}\)
\(F\) 分布的上 \(\\alpha\) 分位点通过查表获取,不在表上的通过上面的性质公式换算。
样本均值和方差的性质
**设总体 \(X\) (不管服从什么分布,只要均值和方差存在)**的均值为 \(\\mu\), 方差为 \(\\sigma^{2}\), $ X_{1}, X_{2}, \cdots, X_{n}$ 是来自 \(X\) 的一个样本 \(, \\bar{X}, S^{2}\) 分别是样本均值和样本方差, 则\(E(\\bar{X})=\\mu, \\quad D(\\bar{X})=\\sigma^{2} / n\),\(E\\left(S^{2}\\right)=\\sigma^{2}\)
\(\\begin{aligned} E\\left(S^{2}\\right) \&=E\\left\[\\frac{1}{n-1}\\left(\\sum\_{i=1}^{n} X\_{i}^{2}-n \\bar{X}^{2}\\right)\\right\]=\\frac{1}{n-1}\\left\[\\sum\_{i=1}^{n} E\\left(X\_{i}^{2}\\right)-n E\\left(\\bar{X}^{2}\\right)\\right\] \\ \&=\\frac{1}{n-1}\\left\[\\sum\_{i=1}^{n}\\left(\\sigma^{2}+\\mu^{2}\\right)-n\\left(\\sigma^{2} / n+\\mu^{2}\\right)\\right\]=\\sigma^{2} \\end{aligned}\)
正态总体的抽样分布
设正态分布\(X \\sim N\\left(\\mu, \\sigma^{2}\\right)\), 由前面章节可知相互独立、服从正态分布的多个随机变量的线性组合仍是正态分布:\(C\_{1} X\_{1}+C\_{2} X\_{2}+\\cdots+C\_{n} X\_{n} \\sim N\\left(\\sum\_{i=1}^{n} C\_{i} \\mu\_{i}, \\sum\_{i=1}^{n} C\_{i}^{2} \\sigma\_{i}^{2}\\right)\), 则样本均值\(\\bar{X}=\\frac{1}{n} \\sum\_{i=1}^{n} X\_{i}\)也服从正态分布\(\\bar{X} \\sim N\\left(\\mu, \\sigma^{2} / n\\right)\)
设正态分布\(X \\sim N\\left(\\mu, \\sigma^{2}\\right)\), \(X\_{1}, X\_{2}, \\cdots, X\_{n}\) 是来自总体 \(N\\left(\\mu, \\sigma^{2}\\right)\) 的样本 \(, \\bar{X}, S^{2}\) 分别是样本均值和样本方差,则有 1)\(\\frac{(n-1) S^{2}}{\\sigma^{2}} \\sim \\chi^{2}(n-1)\) 2)\(\\bar{X}\) 与 \(S^{2}\) 相互独立.
设正态分布\(X \\sim N\\left(\\mu, \\sigma^{2}\\right)\), \(X\_{1}, X\_{2}, \\cdots, X\_{n}\) 是来自总体 \(N\\left(\\mu, \\sigma^{2}\\right)\) 的样本 \(, \\bar{X}, S^{2}\) 分别是样本均值和样本方差,则有 \(\\frac{\\bar{X}-\\mu}{S / \\sqrt{n}} \\sim t(n-1)\)
设正态分布\(X \\sim N\\left(\\mu\_1, \\sigma\_1^{2}\\right)\),正态分布\(Y \\sim N\\left(\\mu\_{2}, \\sigma\_{2}^{2}\\right)\), \(X\_{1}, X\_{2}, \\cdots, X\_{n}\) 是来自正态总体 \(N\\left(\\mu\_1, \\sigma\_1^{2}\\right)\) 的样本 ,\(Y\_{1}, Y\_{2}, \\cdots, Y\_{n\_{2}}\)是来自正态总体\(N\\left(\\mu\_{2}, \\sigma\_{2}^{2}\\right)\)的样本, 且这两个样本分别独立。 \(\\bar{X}=\\frac{1}{n\_{1}} \\sum\_{i=1}^{n\_{1}} X\_{i}\),\(\\bar{Y}=\)\(\\frac{1}{n\_{2}} \\sum\_{i=1}^{n\_{2}} Y\_{i}\) 分别是这两个样本 的样本均值; \(S\_{1}^{2}=\\frac{1}{n\_{1}-1} \\sum\_{i=1}^{n\_{1}}\\left(X\_{i}-\\bar{X}\\right)^{2}\),$ S_{2}^{2}=$\(\\frac{1}{n\_{2}-1} \\sum\_{i=1}^{n\_{2}}\\left(Y\_{i}-\\bar{Y}\\right)^{2}\) 分别是这两个样本的样本方差,则有 1)\(\\frac{S\_{1}^{2} / S\_{2}^{2}}{\\sigma\_{1}^{2} / \\sigma\_{2}^{2}} \\sim F\\left(n\_{1}-1, n\_{2}-1\\right)\) 2)当 \(\\sigma\_{1}^{2}=\\sigma\_{2}^{2}=\\sigma^{2}\) 时,\(\\frac{(\\bar{X}-\\bar{Y})-\\left(\\mu\_{1}-\\mu\_{2}\\right)}{S\_{w} \\sqrt{\\frac{1}{n\_{1}}+\\frac{1}{n\_{2}}}} \\sim t\\left(n\_{1}+n\_{2}-2\\right)\),其中\(S\_{w}^{2}=\\frac{\\left(n\_{1}-1\\right) S\_{1}^{2}+\\left(n\_{2}-1\\right) S\_{2}^{2}}{n\_{1}+n\_{2}-2}, \\quad S\_{w}=\\sqrt{S\_{w}^{2}}\)
注意:本节所介绍的几个分布(\(\\chi^{2}\) 分布,t分布,F分布),以及样本均值和方差的性质(除了\(E(\\bar{X})=\\mu, \\quad D(\\bar{X})=\\sigma^{2} / n\),\(E\\left(S^{2}\\right)=\\sigma^{2}\)),都是在总体为正态分布的假定下得到的。
发表回复