Contents
网易杭研总结:数据库高可用技术之道(7)
转载来源: https://zhuanlan.zhihu.com/p/90798512
数据库作为IT系统中最关键的服务之一,其可用性一直是系统设计中的重点考虑因素。同时,由于数据库有数据有状态的天性,数据库高可用有其天然的复杂性和难点,云原生架构下尤其如此,是一个值得深入探讨的课题。本系列文章将基于网易杭州研究院的研究与实践,解析数据库高可用技术要点,梳理主流数据库方案,为数据库技术建设规划提供参考。
本文由作者授权网易云发布,未经许可,请勿转载!
作者:倪山三,网易杭州研究院运维工程师
Catalog
-
- Prologue
-
- 数据库高可用技术要点
-
- 1.1. 冗余设计 — 数据冗余方案
- 1.2. 冗余设计 — 冗余数据间的一致性
- 1.3. 冗余设计 — 实例冗余
- 1.4. 故障切换 — 服务角色
- 1.5. 故障切换 — 故障感知与应对
- 1.6. 故障切换 — 业务连接切换
-
- 主流数据库方案概览
-
- 2.1. 主流数据库高可用功能概览
- 2.2. MySQL数据库高可用功能概览
接上文:
2.1. 主流数据库高可用功能概览
2.1.1. Oracle高可用方案
Oracle服务的高可用设计通常有两种架构选择, 能够满足不同层级的需求.
- dataguard架构
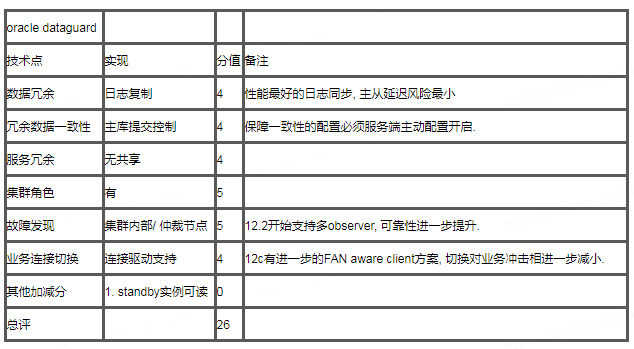
Oracle dataguard + dg broker FSFO + 客户端高可用字符串, 是我们目前最常用的Oracle高可用架构, 相比Oracle其他方案的主要优势就是对软硬件环境要求低, 性价比高. 普通服务器+TCP网络即可组建能够自动切换的高可用集群, 同MySQL的要求无异, 各方面都很优秀.
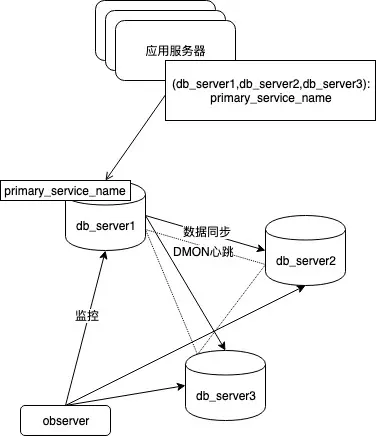
图45, oracle dataguard高可用方案的特征, 日志同步, 仲裁切换, 通过高可用连接字符串和服务名定位主节点, 客户端实现连接切换.
- RAC和MAA架构
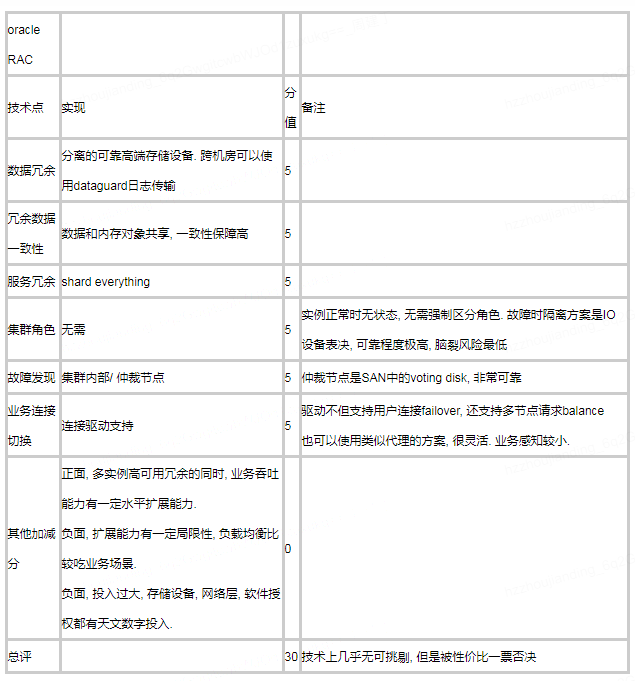
RAC是完全不同的另一条技术路线, 通过机房内的SAN存储和服务器间告诉互联网络实现了内存和存储的共享, 做到了存储于计算形式上分离, 数据高可用由高端存储设备保障, 实例高可用通过无状态节点间客户端自动切换实现. 在RAC集群外, 如果想要实现存储无法实现的超远距离跨机房冗余, 可以在RAC集群间再部署基于日志传输的dataguard数据复制, 组合起来就是所谓MAA架构. 技术方面可以说无可挑剔, 但是对软硬件投入实在太高, 对互联网网业务来说没有性价比可言.
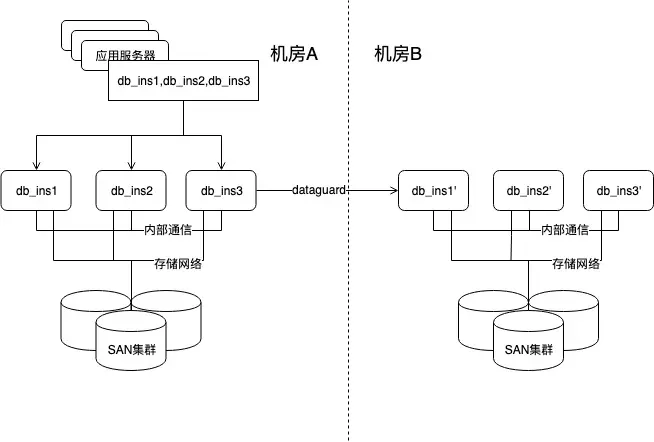
图46, Oracle MAA架构, 首先属于共享集中式架构, 不是分布式架构, 水平扩展能力有一定局限性, 但是根本问题还是投入太高.
2.1.2. Redis高可用方案
Redis是我们线上使用最广泛的NoSQL之一. 由于功能上支持大量复杂数据结构, 相比memcache, 也是更受业务欢迎的kv系统. 其高可用架构也是业务系统建设中的重点. 通常有两种方案可以供选择.
- Redis cluster
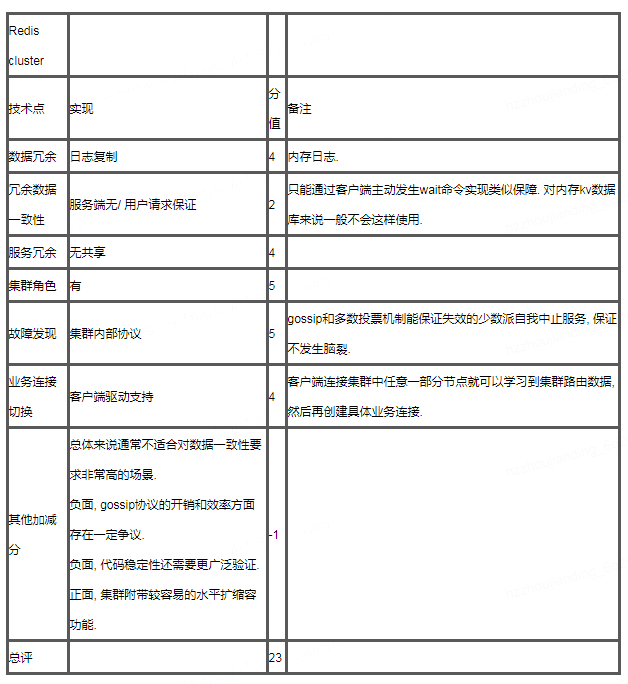
cluster架构是我们目前主推的Redis架构, 也是目前看最有竞争力的方案. 其最大的优势倒不是高可用保障方面, 而是较容易的水平扩缩容, 其他方面来说redis cluster也没有太明显的短板. 就高可用功能来说, 除了服务端的发现, 选举, 切换外, 客户端这边对failover的兼容也是重点考察项. 这里提一下, 云音乐这里我们通过自己封装的客户端实现了开源驱动在cluster架构下不支持的mget, pipline等操作, 也兼容集群动态扩缩容和故障切换, 是对cluster业务功能非常有价值的补充.
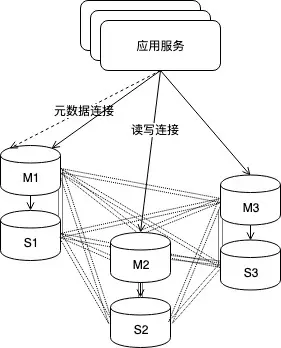
图47, Redis cluster架构, 工程上的原因, 我们的服务都是以主从绑定的形式加入到集群中的, 从节点也参与gossip心跳和投票. 由于cluster的客户端对切换的感知是从路由表发生变化发现的, 因此客户端必须要兼容路由修改后的业务连接重建逻辑.
- Redis sentinel
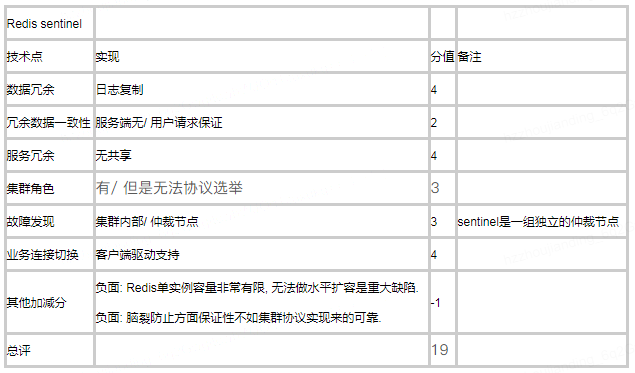
与Redis cluster本身是一种分布式集群不同, Redis sentinel是一种独立服务, 仅做高可用功能, 作为监控并负责Redis master-slave架构主从切换到仲裁服务存在. 因此sentinel和redis主从集群是一对一的关系, 就是说一个sentinel负责的大量redis主从对间是没有集群关系的, 这意味着这是一种无法实现分布式水平扩缩容的架构. 这是sentinel最致命的问题. 其他方面, 作为高可用服务, sentinel最大的问题就是角色切换操作是由sentinel下发到各节点的, 因此存在故障节点操作不成功, 出现双主脑裂的情况是可能的, redis只能通过增加sentinel数量, 确保总有sentinel能够联通故障节点来降低脑裂问题的风险, 但是毕竟无法根治.
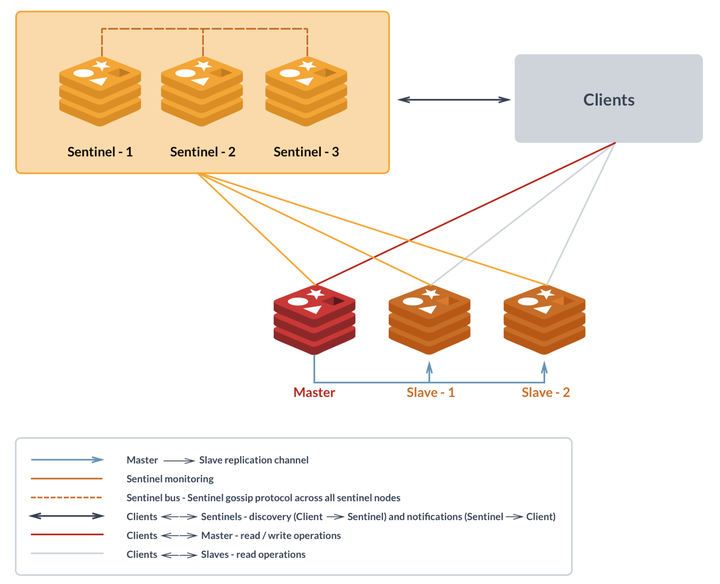
图48, sentinel架构下, 用户客户端是填写并连接sentinel地址的, 由sentinel反馈给业务当前应当读写的Redis主库地址. 底层Redis发生故障切换时也是sentinel主动通知客户端做连接切换.
举一个脑裂的例子说明为什么说故障切换不能依赖对故障节点的外部操作成功. 如下场景, 如果由于某个master同sentinel的网络连接出现问题, 会被认为该master离线, 需要切换, 但是切换后意味着sentinel无法通过网络将老master设置为从角色, 如果该master本身除了到sentinel网络外没有其他问题, 应用服务器还能够正常连上, 那么就会出现同时有两个数据不一致的主库可写的情况.
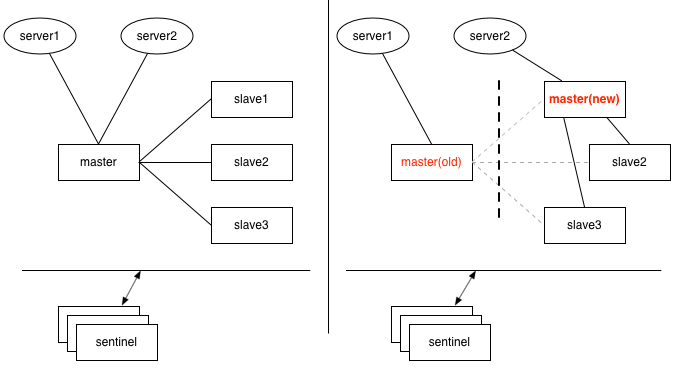
图49, sentinel作为仲裁服务, 需要确保随时能够连通集群中的节点, 一旦由于sentinel和节点间网络问题造成的切换, 很容易出现脑裂的情况. 解决方案是增加sentinel数量和分布, 减少出现所有sentinel无法连通节点的可能性.
在Redis cluster还没有广泛使用的时期, 为了实现Redis分布式集群, 主要有两个方案, 第一个是类似memcache的客户端一致性hash分片, 另一个是之前提到过的twemproxy代理, 由twemproxy封装的客户端来做hash分片. 无论哪个方案高可用方面都没有太大问题, 但是都存在虽然实现了分布式, 但是无法轻易调整数据分布导致无法扩容的问题. 因此都是被淘汰的方案.
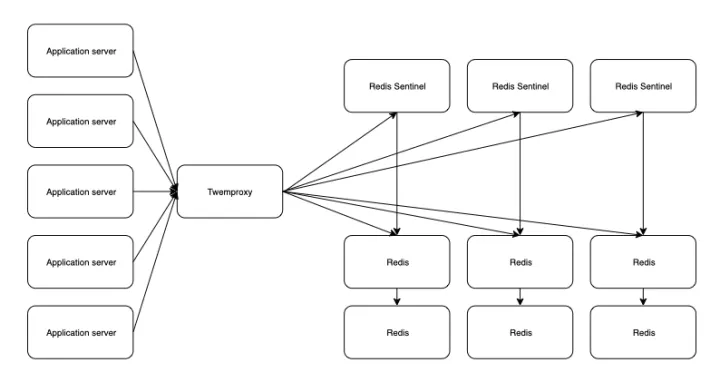
图50, 第二次出现的Twemproxy架构图.
2.1.3. MongoDB高可用架构
几年前我表达过一个观点, 如果我在一个没有太多数据层中间件开发能力的创业型公司, 那么MongoDB一定会是数据存储层重要解决方案之一. 原因是在众多数据库产品中, MongoDB架构方面的功能考虑的最多, 从高可用到水平分布式, 再到扩缩容, 让选型的人非常舒服. 在现在, 一方面云原生方面出现了Aurora和PolarDB这类不怎么需要扩容的大容量服务方案, 另一方面也出现了业务更熟悉的SQL兼容的TiDB等NewSQL方案, 可是在数据库选型中MongoDB依然是不可忽视的一种重要技术方向 —— 从它诞生就设计好的这些功能今天看也依然先进.
MongoDB的高可用我们前面提过成为ReplicaSet, 是一种非常干净的架构, 日志复制 + 集群协议选主 + 客户端兼容切换. 除了冗余数据一致性保障方面有点遗憾外其他都很不错.
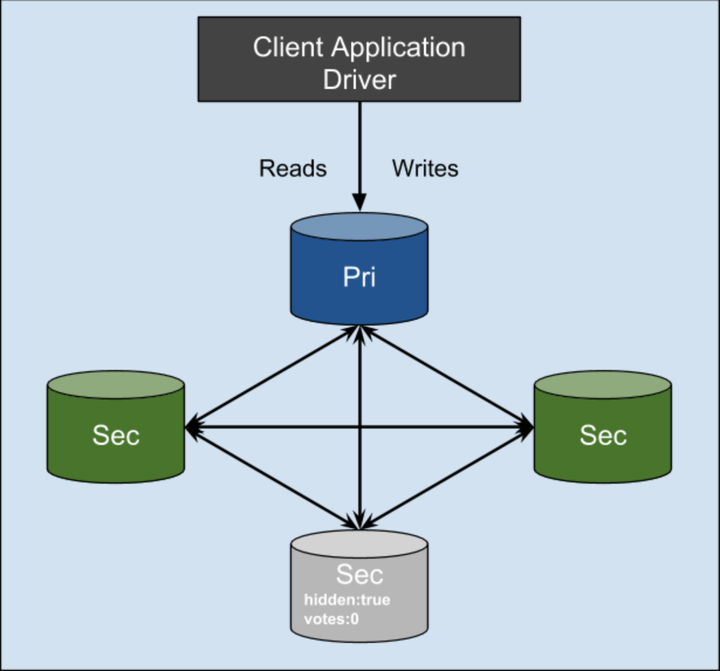
图51, MongoDB ReplicaSet, 如图所示, 参与选举的节点配置也很灵活, 设计的足够好了.
在有了ReplicaSet高可用集群的基础上, 将一组ReplicaSet作为一个数据分片, 上层再来做分布式集群建设, 这就是MongoDB能够动态扩缩容的分布式集群方案MongoDB Sharding cluster. 数据采用range维度分段分布式存放, 引入查询路由服务mongos, 底层节点切换由路由服务兼容, 路由高可用可以通过LB服务或客户端兼容实现. 虽然range分布式比较挑业务场景, 或者需要业务做分片key散列改造, 但是架构设计上还是非常优秀的整体方案.
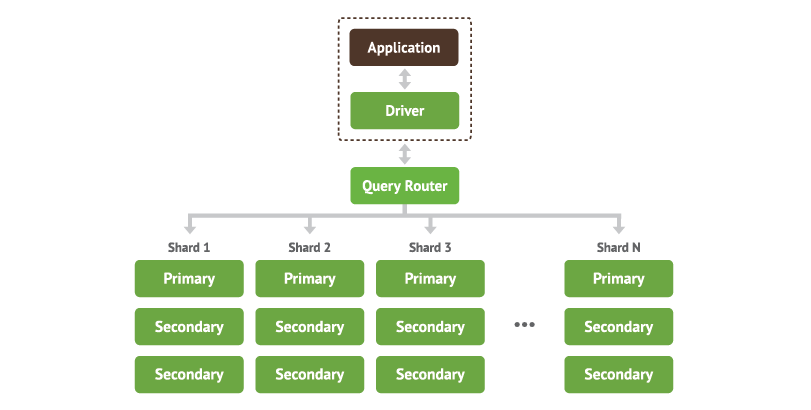
图52, MongoDB sharding cluster分布式架构, 每个数据分片都是一组ReplicaSet高可用集群. 兼容底层节点切换的工作由业务客户端变成了查询路由服务来做.
2.1.4. HBase高可用架构
HBase高可用在第一篇章中介绍的较详细了, 这里就不再详细展开. 主要说明一点, HBase在要求数据一致的情况下, 其高可用切换涉及到持久化日志HLog的切分和回放, 保证region漂移后数据完整, 这一机制导致HBase的切换时间往往难以掌控, 受到需要move的region数量, HLog数据量, 写入吞吐量, 失效主机flush进度等多方面影响, 线上经验来看有时甚至需要较长时间, 最后不得不决策通过清理HLog, 放弃部分数据, 来提高恢复时间, 这一点比一开始就放弃一致性更糟糕.

2.1.4. NewSQL —— TiDB高可用架构
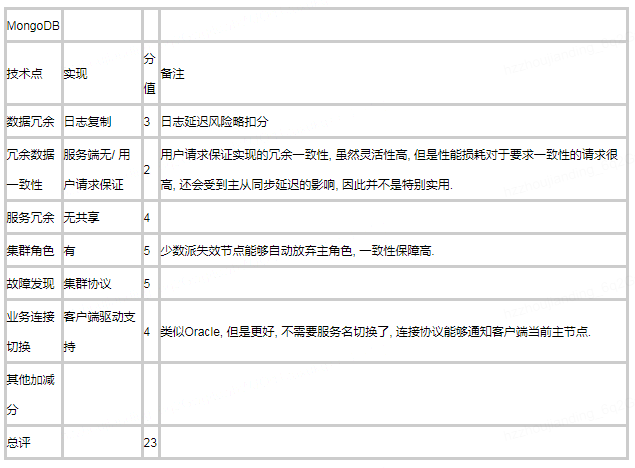
虽然TiDB还算不上生产环境常见方案, 但是还是必须要提一下. 仅仅从高可用角度看, TiDB没有太明显短板, 硬要说的话, 由于MySQL驱动本身对高可用特性的支持以及开源MySQL代理服务不够强大, 使应用接入方案有一定局限, 同时TiDB为了完全兼容MySQL, 也没有提供定制的接入方案. 其他方面都很完美, 可以从下面的评分表看到.
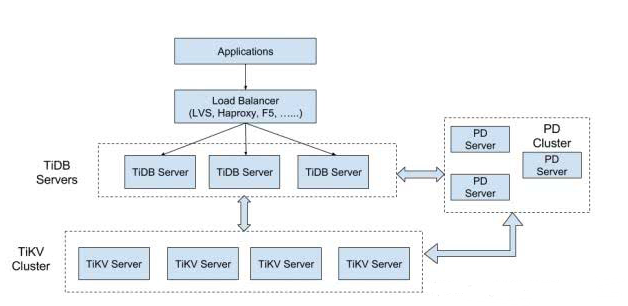
图53, 第二次出现的TiDB架构图. 高可用方面非常到位.
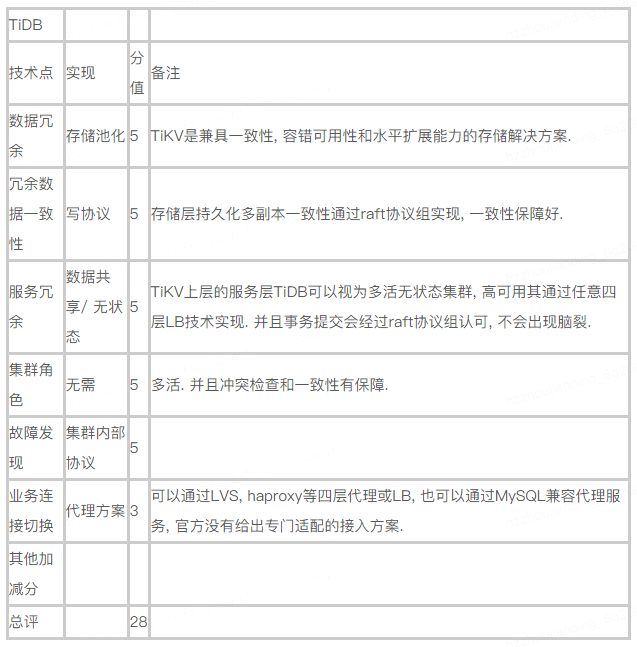
并且我们要花额外时间再展开介绍一下TiDB, 目前我认为TiDB的显著优势在于:
- MySQL兼容性强, 业务接入容易.
- 接入TiDB后相较于传统MySQL, 用户获得了服务高可用能力, 局部故障时数据一致性, 以及集群吞吐能力水平扩展三种非常有价值的能力增强.
- 并且TiDB技术路线上通过对接spark引擎, 集群内部的列式存储等方式, 努力向着HTAP混合数据库发展, 较传统MySQL -> ETL -> Hadoop模式下需要非常复杂流程来进行OLTP数据到OLAP平台传输的架构有着很强便利性, 数据实时性和一致性提升, 我认为对非常依赖数据分析能力的小规模创新型团队很有价值.
- 今后数据库业界趋势越来越向着云原生方向发展, 但是云原生架构和几大云平台自身基础架构密切绑定, 脱离了云平台, 外界几乎没有能力在存储, 网络, 事务引擎几个核心环节复用云原生的任何技术和优势. TiDB则是开源的对标方案, 是目前能够看到的构建私有云原生数据库完整解决方案中最好的选择之一.
但是TiDB到:
- 事务冲突检测中的乐观锁模型极端挑业务场景, 必须也正在被官方正视, 并解决. 否则永远无法广泛运用于OLTP业务. 更重要的一点是绝不能轻视甚至放弃OLTP市场.
- 代码健壮性和稳定性需要更多应用案例验证.
- HTAP方案需要案例与开发框架支持, 需要满足习惯基于Spark和Impala开发的数据分析师的需求, 例如别人不一定适应直接基于在线表结构进行开发等等.
- 整体架构, 特别是代理接入层上需要有自己完善的解决方案, 必要时可以抛弃MySQL全兼容. 例如既然短时间无法解决并发更新提交冲突问题, 那么是否能够在代理层做到冲突事务尽量路由到一个TiDB来服务.
- 私有云原生部署和管理, 需要完整可行的方案.
我个人非常看好TiDB, 认同其技术和价值, 也希望时机成熟的时候能够尽可能推广运用TiDB. 但是目前为止, 还没有看到其取代网易现有数据库水平分布式方案的可行性与必要性.
相关阅读推荐:
发表回复