Contents
网易杭研总结:数据库高可用技术之道(5)
转载来源: https://zhuanlan.zhihu.com/p/88462571
数据库作为IT系统中最关键的服务之一,其可用性一直是系统设计中的重点考虑因素。同时,由于数据库有数据有状态的天性,数据库高可用有其天然的复杂性和难点,云原生架构下尤其如此,是一个值得深入探讨的课题。本系列文章将基于网易杭州研究院的研究与实践,解析数据库高可用技术要点,梳理主流数据库方案,为数据库技术建设规划提供参考。
本文由作者授权网易云发布,未经许可,请勿转载!
作者:倪山三,网易杭州研究院运维工程师
Catalog
-
- Prologue
-
- 数据库高可用技术要点
-
- 1.1. 冗余设计 — 数据冗余方案
- 1.2. 冗余设计 — 冗余数据间的一致性
- 1.3. 冗余设计 — 实例冗余
- 1.4. 故障切换 — 服务角色
- 1.5. 故障切换 — 故障感知与应对
- 1.6. 故障切换 — 业务连接切换
-
- 主流数据库方案概览
-
- 2.1. 主流数据库高可用功能概览
- 2.2. MySQL数据库高可用功能概览
接上文:
1.5. 故障切换 — — 故障感知与应对
在MySQL, Oracle(非RAC), Redis, MongoDB等承载线上大部分数据的主流数据库服务中, 无论是存储损坏还是服务宕机, 都需要引入切换环节. 一方面要引导用户去使用冗余资源, 这个在1.6会详细讨论; 另一方面, 集群本身要做好冗余资源提供线上服务的准备. 简单来说, 如果集群有角色之分, 那么就要做好角色切换工作, 这里面有两个目的:
- 第一, 故障实例要设法保证不再可写入.
- 第二, 合法的冗余服务要开启写入, 承接线上业务流量.
从1.4我们知道, 有角色集群才是真正的集群, 其故障感知与角色选举完全可以在集群内部完成. 而无角色集群其实是一种独立实例的集合, 只能靠外部工具来帮助业务起到切换角色目的. 所有有了1.5.1和.1.5.2两种方案. 可以说切换时候的故障感知本质上就是内部或外部的主从角色选举过程.
1.5.1. 内部协议
我最欣赏的就是集群通过内部协议来完成故障发现, 确认与角色切换流程的实现, 参考zookeeper. 有谁对作为分布式协调器存在的zookeeper自身高可用机制有疑虑吗? 数据库的目标就是高可用标准, 无论是可靠性还是数据一致性, 都要向zookeeper靠拢.
在数据库领域, 传统上几个有代表性的例子, MongoDB ReplicaSet和Redis Cluster, 虽然同zookeeper的实现相差甚远, 但是功能上依然令人满意.
MongoDB的ReplicaSet是一个一主多从的架构, 同传统MySQL最大的不同时, 集群节点有心跳, 区分角色, 会通过心跳来确定各自的存活状态, 并通过多数节点投票来踢出故障实例, 并选举主新的主实例, 这一切都在集群内部自动完成, 无需外部介入. 虽然MongoDB在数据同步上是简单的异步日志同步, 但是在可用性选举上使用了足够可靠的raft协议(3.2后, 3.2前更简单的bully算法). 以此为基础, MongoDB的高可用集群切换成功率和可靠性是很有保障的.

图31, MongoDB ReplicaSet的主库失效选举.
Redis cluster则是更激进的思路, 没有对单组主从构成的小集群内做沟通协议 (而在sentinel时代, 是类似于这样做的) , 而是将某个主节点的存活判断交给了整个集群所有节点形成的gossip协议网络. 通过点对点形成网状的pingpong心跳, 形成对失效节点的共识, 并依据多数认同原则进行选举. gossip网络中累积对某个失效节点的pong超时, 如果数量过半, 则集群达成共识认为某节点失效. 进而如果配置中该节点的从库在集群共识中是存活节点, 由预备成为新主的该节点发起投票, 并达成共识替代失效节点. 虽然gossip网络开销和可扩展性上有一些讨论空间, 但是Redis cluster的整个故障节点发现, 踢出, 选举新主并恢复服务的全自动化流程, 我们认为是可靠的.

图32, Redis cluster中的故障发现与选举.
接下来是比较新的例子, 我们前面也提过, MySQL高可用的好时代可能是要来临了. MGR架构下的MySQL, 不但能够通过paxos协议通信实现MongoDB ReplicaSet的故障节点自动发现, 踢出, 重新选举恢复流程, 甚至连事务的提交流程也要通过paxos group认可, 在主从数据一致性保障上更有优势. 当然话说回来, 较重的提交流程也对MGR造成一定的功能限制, 这部分这里就不展开了.

图33, MGR的group实现架构. 所有事务的提交都要通过paxos协议得到集群认可, 数据一致性方面有着非常大的改善. 但是协议环节依然依赖binlog.
另外, Oracle的dataguard架构可以开启dg broker功能. 虽然没有dg broker也能够构建dataguard架构, 但是无法实现故障自动切换. 但是如果启用dg broker并启用FSFO(fast-start failover)功能, 则某种意义上可以算在集群内部完成了故障发现与自动切换.

图34, Oracle dataguard broker架构. 如果启用dg broker, Oracle进程组里会增加一个专门用于内部监控通信的DMON进程. 但是进行自动failover的实际上是独立的observer仲裁节点.
还需要提一点, 要想形成能够在集群内完成失效节点裁定和新节点选举的数据库, 通常是需要3个以上奇数节点参与的. 这比较一主一从的两节点冗余方案资源上肯定要多投入一些. 但是也有解决方案, 比如MongoDB允许集群加入只参与投票, 不复制数据的arbiter节点, Oracle dg broker中的observer节点等, 节省硬件成本.
这里举的一些例子都是shared nothing架构的常见数据库. 其他分布式数据库, 例如HBase实际上也是有failover过程的, HBase是通过Zookeeper来裁定RS服务失效, 然后由master来分配失效RS上的region给其他RS, 也是集群内部发现并解决切换问题.
1.5.2. 外部检测
前面都是正面案例, 数据库能集群内部自己解决故障发现, 角色切换, 服务恢复全过程. 下面要来讲一些不那么优雅的实现. 如果数据库主和从之间没有形成可靠的集群协议与选举算法, 那么就需要外部程序来介入服务故障发现与切换流程.
由于没啥新意, 只举一个例子, MySQL如果不使用MGR, 那么就是要通过外部服务来监控主从状况并完成主从切换. 比如大名鼎鼎的MHA.
MHA是一组独立于数据库运行的脚本程序, 主要作用的持续探测目标数据库主从库健康状况. 如果主服务发生故障, 则执行一系列预设的操作. 详情可以看下面的MHA工作流程图:

图35, MHA探测和切换流程, 不细讲了, 黄色的四个方块的关键点, 都需要DBA根据具体需求自行完善, MHA本身仅提供触发时机, 不负责具体切换工作.
切换工作时机需要DBA来设法实现, MHA仅是一个监控触发器, MHA本身功能最大的亮点在于在一个特定历史时期, 想尽办法保证数据一致性. 在出现semi-sync技术前, MySQL只有异步复制, 如果主库宕机, 很可能日志没有传到从库, 造成切换后数据丢失, MHA则是能够在主库实例宕机, 但是服务器和操作系统健在的情况下, 通过scp帮你把从库少的主库binlog传到从库尝试补全数据. 但是这个功能在实际运用中能用的上的概率其实非常低, 并且我们前面提过的semi-sync技术也相对成熟了.

图36, MHA的主要亮点是补日志保证数据一致性, 但是实用性方面并不高.
以MHA为例, 外部高可用工具实际上需要帮助自身没有相关功能的数据库实现如下几个需求:
-
判断集群中某个节点故障, 并且要防止监控程序自身由于网络割裂出现误判
-
- MHA: 通过建立访问连接, 下发探活请求
- MHA: 判断出现可能需要切换的主库问题时, 允许通过ssh到另一台监控服务器调用预设脚本复核
-
设法将故障节点从用户可访问状态中隔离
-
- MHA: 允许通过ssh到故障主机, 执行shutdown脚本, 脚本内容自定义, 可以自由选择隔离手段.
-
选择适当的冗余节点成为新主库
-
- MHA: 如果故障主库所在主机尚能ssh, 尝试修复受监控从日志. 选择受监控从中日志最接近故障主的节点, 保证数据尽量少丢失.
- MHA: 还要修改主从拓扑, 将集群中出新主外其他从库的复制关系切换到新主库
-
设法将用户请求引导至新主库
-
- MHA: 允许两次调用master_ip_failover_script脚本, 脚本内容自定义, 除了ip切换外可以选择其他手段.
无论采用何种外部检测和切换工具实现高可用功能, 基本都是这样一个通用设计.
1.5.3. 防抖动
包括内部和外部实现的切换方案, 有两个非常重要的点要考虑. 故障检测, 切换决策, 切换操作过程中首先要预先考虑到的一种情况是防抖动, 这是鲁棒性设计中一个基础概念, debounce. 网络和服务本身都可能存在各种原因造成的短暂失效, 比如网络异常流量导致短暂拥塞, 服务程序GC或业务瞬时流量导致的短时间过载等.
- 高可用切换通常要伴随一定的用户不可用时间, 同时还可能存在数据一致性风险, 所以切换是否必须执行这个决策本身必须慎重.
- 如果监控判断故障节点恢复, 必须谨慎考虑是否要发生二次切换.
- 如果局部网络存在问题, 监控测遇到连续的原主, 新主, 后续新主… 接连出现问题时怎么办.
对于数据库来说, 当然最关键的是考虑第一点. 由于短暂间歇的服务终端其影响可能还没有切换本身带来的业务冲击来的高, 进一步的, 如果切换决策机制做的不好, 发生连续切换造成的业务影响肯定是远大于环境抖动. 另外一方面, 如果一个环境出现频繁网络问题, 对业务来说只要数据库主和备都在这个环境中, 不管是否切换, 其影响都是无法通过数据库高可用机制消除的, 为此跨机房, 跨独立网络环境的冗余和切换策略有其必要性. 因此我们说数据库防抖动主要是两方面设计:
- 切换决策
- 冗余策略
在切换决策方面, 解决方案其实非常简单, 除了通过投票等方法保证主服务故障正确性, 消除监控节点本身单点或点对点问题的影响外, 另外一个设计要点就是给予足够的观察窗口, 忽略短暂失效.
举些例子, 时间最短的redis cluster的pong超时时间默认15s, HBase zk超时时间默认30s, Oracle DG broker heartbeat超时时间30s. 而我们自己做的某监控框架对MySQL不可用的判断条件, 不但要等待一定的超时时间, 还要在sleep一定时间后多次重试都返回同样的超时或错误, 才判定主库失效.
而冗余策略方面, 一般数据库做高可用切换, 不会允许重新加入集群的失效节点立刻成为高可用切换目标, 两次切换时间间隔也必须给与保证. 然后就是做整体方案设计的时候对关键服务要给与跨机房保护, 切换策略分同机房冗余到跨机房冗余两步, 不会纠结于一个机房内的频繁问题.
总之防抖动实际也不是数据库特有的问题, 任何程序设计的时候都要考虑这个方面的问题. 这里专门提出来讲是因为要解释一下, 传统shared nothing的数据库高可用其特殊性在于切换对业务和数据库一致性影响通常较大, 所以必须谨慎, 这也是为什么数据库高可用自动切换, 恢复服务的时间不会非常短, 必然需要数十秒到数分钟级别的重要原因之一. 影响切换速度的其他因素还有很多, 比如等待日志补齐保证数据一致性, 对原主库做IO fencing, 漂移资源操作…等等, 比如Oracle dataguard架构在切换的时候为了切换controlfile角色, 需要重启实例, 时间就一下加长了.
1.5.4. 防脑裂
脑裂是数据库高可用切换过程中最大的风险. 假设内部或外部选举机制没有做的很好, 老的主库和新的主库或者监控服务间网络中断, 这是新主切换角色开放写功能, 然后应用服务器这边同新老两个主库的网络没有问题, 由于数据库应用通常是长连接, 就会出现如下图所示的两个独立数据库都可读写的情况. 这是最可怕的情况, 在我看来比数据一定时间不可访问危害更大, 因为用户不但会访问和产生大量不一致数据, 并且这个不一致问题是非常难以修复的, 必定会丢失大量数据.
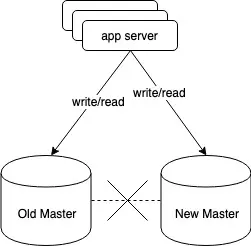
图37, 脑裂的情况. 新老两个主库的数据不一致的情况会不断加重, 这通常意味着数据大量丢失.
防止脑裂也是鲁棒性设计非常通用的一个项目. 在数据库这里防止脑裂有两个关键点:
- 新主的合法性, 必须是一个全局共识.
- 一旦确定要切换, 不管老主库是否还可用, 老主库必须被隔离.
对于新主的合法性, 我们有一些方案来保证:
- 通过选举协议, 集群多数节点(majority, 最少一半以上)接受新主提案, 例如我们前面提过的MongoDB ReplicaSet, redis cluster, MySQL MGR方案都是这个路数, 包括Zookeeper也一样, 绝对不能允许单一节点自行提升角色.
- 还可以引入第三方仲裁者, 比如Oracle DG broker的observer, RAC中的voting disk, 就是有较高权限的仲裁者, 比如两个实例之间的心跳中断, 单到仲裁者心跳未中断, 这时候就会采取先到即存活判定, 一旦有脑裂风险, 那么必须强制抛弃一个节点.
- 进一步的, 如果采取外部监控和仲裁, 仲裁者本身也要具备多数共识合法性保证, 例如redis sentinel架构多个sentinel的切换共识数配置, 我们自研的mysql warden高可用框架的切换投票机制等.
在确保新主合法性, 并达成必须切换的共识后, 还要做的就是确保老主库不再能写入数据 (最好读也不行) . 以前在使用共享存储接管式高可用的时候一搬把这个过程成为IO fencing, 是集群理论中防止脑裂损坏数据的必要操作. 对于数据库的解决思路:
- 最优秀的做法是类似Zookeeper, MongoDB, MGR这些, 一旦某个节点发现对自己的身份认知得不到多数共识的时候, 自行终止提供服务. 这是在无论出现何种网络割裂情况下都能够奏效的最佳方案.
- 或者交由仲裁服务或资源来判断, 失去仲裁支持的节点禁止服务或听从仲裁安排. Oracle一般是这个方案.
以上两个方案都是基于节点有防止脑裂进入禁止写入状态的机制的前提下的, 但是对于MHA + MySQL这样外部监控+无角色松散集群的架构下, 脑裂着实是个巨大的难题. 首先选举合法性方面, MHA虽然允许通过第二台服务器复检, 但是可靠性远不如选举协议. 其次, MySQL没有集群意识, 是否可写完全受外部控制, MHA的隔离方案正常来讲是ssh到老主库上去kill 老主库实例. 但是线上问题非常复杂, 主机不可SSH, 操作系统不能fork 新进程, 但长连接的数据库还能写入数据的情况不算罕见. 因此我们说MHA + 传统MySQL是个非常不靠谱的方案.
对于MySQL这类无集群角色意识的数据库, 有必要采取非常强制的失效主库隔离方案, 而且这个方案还不能依赖失效资源自身, 不能指望出问题的节点在软硬件方面听从监控服务指挥, 最好要设法通过外部断网断电手段实现隔离, 比如将MHA的老主库shutdown脚本机制改造为调用硬件接口对故障节点带外关机等.
综上所述, 还是尽量选择靠谱的高可用架构吧…
推荐阅读:
发表回复