网易杭研总结:数据库高可用技术之道(2)
转载来源: https://zhuanlan.zhihu.com/p/84461585
数据库作为IT系统中最关键的服务之一,其可用性一直是系统设计中的重点考虑因素。同时,由于数据库有数据有状态的天性,数据库高可用有其天然的复杂性和难点,云原生架构下尤其如此,是一个值得深入探讨的课题。本系列文章将基于网易杭州研究院的研究与实践,解析数据库高可用技术要点,梳理主流数据库方案,为数据库技术建设规划提供参考。
本文由作者授权网易云发布,未经许可,请勿转载!
作者:倪山三,网易杭州研究院运维工程师
Catalog
-
- Prologue
-
- 数据库高可用技术要点
-
- 1.1. 冗余设计 — 数据冗余方案
- 1.2. 冗余设计 — 冗余数据间的一致性
- 1.3. 冗余设计 — 实例冗余
- 1.4. 故障切换 — 服务角色
- 1.5. 故障切换 — 故障感知与应对
- 1.6. 故障切换 — 业务连接切换
-
- 主流数据库方案概览
-
- 2.1. 主流数据库高可用功能概览
- 2.2. MySQL数据库高可用功能概览
1.2. 冗余设计 — — 冗余数据间的一致性
至此, 我们讨论了三种实现数据近实时冗余的方案, 作为核心资源 —— 数据 —— 的高可用保障机制. 在实现这些方案的过程中, 会引入下一个技术要点, 如何保障被复制冗余的数据不丢失.
一致性在这里有两层, 一层是宏观来讲, 对于数据库来说事务的一致性. 另一层是对于存储数据来说字节一致性. 很显然, 基于事务日志同步的数据是要求事务结果一致, 基于存储的方案是要求字节一致性.
1.2.1. 事务持久化标识控制
这是针对日志同步方案中, 事务结果一致性保证的较通用方案. 数据库的事务的持久化特性要求描述为“提交成功的事务”都能保证不会发生丢失. 而commit在数据库操作中是一个显式操作, 因此我们对数据库冗余的要求就是在主库commit完成的事务, 主库和冗余库都不能丢失. 所以在使用日志进行数据冗余复制的系统中, 通常是在用户发起commit命令和系统返回commit成功这中间的时间段, 来做多份数据一致性保障工作.
在传统RDB中, 数据持久化不丢失的标准并不是指修改的数据内容都被更新到磁盘, 而是记录数据修改的事务日志被持久化到磁盘即可. 这是因为在机械盘时代, 通常我们认为被修改数据分散在磁盘的各个角落, 而事务日志是一份顺序写的流水文件, 随机写脏数据同顺序写日志效率有数十倍的差距, 因此日志持久化一直是RDB持久化的广泛标准. 正好, 日志同时也是数据冗余复制的主要工具.
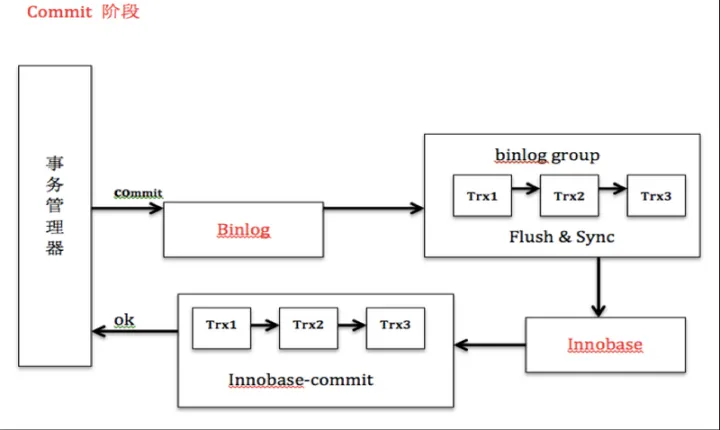
图15, MySQL最常用的事务引擎innodb的commit持久化流程, 我们看到由于MySQL有两种事务日志, binlog与innodb redolog, 而提交成功的标志是两种事务日志完成落盘. 这中间同被修改的数据落盘没有显著的关系. 两种日志中, binlog就是用于主从复制数据的事务日志.
那么在有从库的场景中也一样, 在一个要求主从保证一致性不能丢失数据的冗余数据库系统, 只要每次用户发起commit, 相关事务日志不但主库落盘完成, 还要传输到从库并且落盘完成, 再返回给用户commit成功, 那么就可以认为数据在主库和冗余库都完成了持久化. 我们来看看比较有代表性的方案流程:

图16, Oracle同步日志传输架构. 具体哪个进程做什么不用太在意, 总之就是用户commit成功的确认(标号3)要求在日志远程持久化成功之后.

图17, 相应的, MySQL semisync复制流程图, 可以看到也是通过控制对用户commit请求返回成功时机保证数据远程持久化成功.
通过控制主库commit返回时机, 要求从库事务日志落盘完成再返回主库用户commit成功来保证主从数据一致, 这一方案的主要优势是实现简单, 功能性强, 主库和从库做到了持久化标准一致. 但是也为系统引入一定风险 —— 首先, 事务提交的效率会受到主从间网络延迟的影响, 机房内部环境下, 通常这个影响因素通常不算太大问题, 但是跨地区传输的网络稳定性还是有一定风险; 进一步的, 如果一个主库事务在主库持久化完成, 而从库由于各种问题持久化失败了怎么办? 通常有两个思路:
- 从库日志不可写则主库写不成功, 甚至直接失效. Oracle dataguard最强一致性保证的最大保护模式即是采用该方案. 因此如果只有一个冗余从库的情况下, 相当于为系统引入一个致命的故障点.
- 从库日志可写的情况下保证要求从库同步持久化, 一旦各种原因造成从库日志不可写, 主库在等待一定超时时间后放弃主从一致性要求, 忽略从库现状, 降级为完成异步复制. 大部分数据库均提供这个折衷方案, 例如等待200ms后commit自动放弃从库持久化要求, 返回给用户成功. 这一方案首先在网络波动的时候可能造成主库commit效率卡顿, 但是主要问题还是太过宽松, 没能从根本上解决数据一致性问题.
出于系统设计的考虑, 解决上述问题的方案就是针对不稳定点再次增加冗余度, 也就是增加从库数量. 以MySQL的semi-sync为例. 系统允许DBA通过配置rpl_semi_sync_master_wait_for_slave_count参数来控制在多个从库的情况下, 多少个从库返回日志写成功主库认为commit成功.

图18, MySQL中rpl_semi_sync_master_wait_for_slave_count的作用.
在这一条件下, 如果2从库中一个从库成功即返回commit ok, 那么一个从库故障不会影响主库. 如果3从库中2个成功返回commit ok, 那么相当于制造了一个小的多数投票机制. 总之都能够解决从库单点问题.
这里还要提一个非常有意思的保障机制. 对于MongoDB来说, 虽然主从通常只提供异步复制, 无法在服务层面控制多副本冗余成功. 但是MongoDB允许在调用写接口的时候主动要求某个请求等到从库接受到数据后才返回成功, 相当于将服务端的冗余安全设置放到了每个写请求层面里控制, 这一机制被称为Write Concern. 这个机制其实在Redis主从架构中也有类似表现, Redis方面要求应用自己通过WAIT命令确保写入的消息同步到从库成功, 看来NoSQL比较偏好这类非强制性的机制.
db.products.insert(
{ item: "envelopes", qty : 100, type: "Clasp" },
{ writeConcern: { w: "majority", wtimeout: 5000 } }
)
# writeConcern 代表这次insert要求多冗余持久化成功
# w: "majority" 代表写要求多数副本冗余成功
# wtimeout: 5000 代表如果5s内不能成功持久化完成, 则忽略从库问题1.2.2. 写协议控制
在1.1.3中我们介绍了计算存储分离的技术架构. 在这一架构方案中存储服务如何保证数据多副本冗余的同时数据一致, 相关技术栈深度较大, 我们还是重点讲数据库架构, 不打算在这里继续展开, 我们仅举一些具有代表性的例子说明. 总之, 对于存储层同步和数据池化服务方案实现数据冗余的场景下, 存储数据的一致性通常由多副本一致性写, paxos, raft, zab等一致性协议来控制冗余间的数据一致性.
以HBase的HDFS存储服务为例, 向HDFS写数据的时候, 首要DN接收到数据后, 会同时传输到多份冗余DN, 当冗余写全部完成后才能返回写成功.

图19, HDFS数据块冗余示意. 正常情况下, 这是一个一次写入要求多份同步完成的一致写.
再以TiDB的TiKV存储服务为例, TiKV在Raft协议保证写一致性方面的工程实践中有非常高效且成功的成果. 写入某个数据的时候, 操作发送给Raft Leader, Leader记录本地日志的同时会通过Raft算法将操作复制到其他的Follower上面, 作为Replicate. 当Leader发现这个操作已经被大多数Follower节点持久化到日志成功, 就认为这个操作Commit成功, 然后再将日志里面的操作解码出来, 执行并且应用到本地状态机.

图20, TiKV的一致性保证采用了Raft协议.
总而言之, 存储池化让数据库无需操心数据方面的高可用问题. 但是也带来了一些新的问题, 例如HDFS强一致写的情况下, 如果要求数据跨远距离机房冗余, 通常对写性能会造成很大影响. 因此以HBase为例, 作为数据库, 也提供了不依赖HDFS的日志同步方案, 用于应对长距离冗余需求.

图21, HBase作为数据库, 在遇到数据需要跨地区冗余的情况下, 也提供了基于事务日志HLog的数据复制冗余方案.
推荐阅读:
发表回复