Contents
MySQL内存参数及调整
转载来源: https://developer.aliyun.com/article/380480
最初来源: 张正 blog:http://space.itpub.net/26355921
MySQL内存参数配置推荐:https://tools.percona.com/wizard
1.慢查询日志:
slow_launch_time=2 查询大于某个时间的值(单位:s)
slow_query_log=on/off 开启关闭慢查询日志
slow_query_log_file=/opt/data/host-slow.log 慢查询日志位置
2.连接数:
max_connections MySQL最大连接数
back_log 当连接数满了后,设置一个值,允许多少个连接进入等待堆栈
max_connect_errors 账号连接到服务器允许的错误次数
connect_timeout 一个连接报文的最大时间(单位:s)
skip-name-resolve 加入my.cnf即可,MySQL在收到连接请求的时候,会根据请求包
中获得的ip来反向追查请求者的主机名。然后再根据返回
的主机名又一次去获取ip。如果两次获得的ip相同,那么连接就成功建立了。
加了次参数,即可省去这个步骤
NOTES:
查询当前连接数:show global status like ‘connections’;
3.key_buffer_size 索引缓存大小,是对MyISAM表性能影响最大的一个参数
32bit平台上,此值不要超过2GB,64bit平台不用做此限制,但也不要超过4GB
根据3点计算:
a.系统索引总大小
b.系统物理内存
c.系统当前keycache命中率
粗略计算公式:
Key_Size =key_number*(key_length+4)/0.67
Max_key_buffer_size <>
Threads_Usage = max_connections * (sort_buffer_size + join_buffer_size + read_buffer_size+read_rnd_buffer_size+thread_stack)
key_cache_block_size ,是key_buffer缓存块的单位长度,以字节为单位,默认值为1024。
key_cache_division_limit 控制着缓存块重用算法。默认值为100,此值为key_buffer_size中暖链所占的大小百分比(其中有暖链和热链),100意味着全是暖链。(类似于Oracle Data Buffer Cache中的default、keep、recycle)
key_cache_age_threshold 如果key_buffer里的热链里的某个缓存块在这个变量所设定的时间里没有被访问过,MySQL服务器就会把它调整到暖链里去。这个参数值越大,缓存块在热链里停留的时间就越长。
这个参数默认值为 300,最小值为100。
Myisam索引默认是缓存在原始key_buffer中的,我们可以手动创建新的key_buffer,如在my.cnf中加入参数new_cache.key_buffer_size=20M。指定将table1和table2的索引缓存到new_cache的key_buffer中:
cache index table1,table2 in new_cache;
(之前默认的key_buffer为default,现在手动创建的为new_cache)
手动将table1和table2的索引载入到key_buffer中:
load index into cache table1,table2;
系统中记录的与Key Cache相关的性能状态参数变量: global status
◆Key_blocks_not_flushed,已经更改但还未刷新到磁盘的DirtyCacheBlock;
◆Key_blocks_unused,目前未被使用的CacheBlock数目;
◆Key_blocks_used,已经使用了的CacheBlock数目;
◆Key_read_requests,CacheBlock被请求读取的总次数;
◆Key_reads,在CacheBlock中找不到需要读取的Key信息后到“.MYI”文件中(磁盘)读取的次数;
◆Key_write_requests,CacheBlock被请求修改的总次数;
◆Key_writes,在CacheBlock中找不到需要修改的Key信息后到“.MYI”文件中读入再修改的次数;
索引命中缓存率:
key_buffer_read_hits=(1-Key_reads/Key_read_requests)*100%
key_buffer_write_hits=(1-Key_writes/Key_write_requests)*100%
该命中率就代表了MyISAM类型表的索引的cache
4.临时表 tmp_table_size (用于排序)
show global status like ‘created_tmp%’;
| Variable_name | Value |
| Created_tmp_disk_tables | 21197 | #在磁盘上创建临时表的次数
| Created_tmp_files | 58 | #在磁盘上创建临时文件的次数
| Created_tmp_tables | 1771587 | #使用临时表的总次数TmpTable的状况主要是用于监控MySQL使用临时表的量是否过多,
是否有临时表过大而不得不从内存中换出到磁盘文件上。
a.如果:
Created_tmp_disk_tables/Created_tmp_tables>10%,则需调大tmp_table_size
比较理想的配置是:
Created_tmp_disk_tables/Created_tmp_tables<=25%
b.如果:
Created_tmp_tables非常大 ,则可能是系统中排序操作过多,或者是表连接方式不是很优化。
相关参数:
tmp_table_size 内存中,临时表区域总大小
max_heap_table_size 内存中,单个临时表的最大值,超过的部分会放到硬盘上。
5.table cache相关优化 :
参数table_open_cache,将表的文件描述符打开,cache在内存中
global status:
open_tables 当前系统中打开的文件描述符的数量
opened_tables 系统打开过的文件描述符的数量
如果:
Opened_tables数量过大,说明配置中table_open_cache值可能太小
比较合适的值为:
Open_tables / Opened_tables * 100% >= 85%
Open_tables / table_open_cache * 100% <= 95%
6.进程的使用情况
在MySQL中,为了尽可能提高客户端请求创建连接这个过程的性能,实现了一个ThreadCache池,
将空闲的连接线程存放在其中,而不是完成请求后就销毁。这样,当有新的连接请求的时候,
MySQL首先会检查ThreadCache池中是否存在空闲连接线程,如果存在则取出来直接使用,
如果没有空闲连接线程,才创建新的连接线程。
参数:thread_cache_size
thread cache 池中存放的最大连接数
调整参考:
在短连接的数据库应用中,数据库连接的创建和销毁是非常频繁的,
如果每次都需要让MySQL新建和销毁相应的连接线程,那么这个资源消耗实际上是非常大的,因此
thread_cache_size的值应该设置的相对大一些,不应该小于应用系统对数据库的实际并发请求数。
参数:thread_stack – 每个连接线程被创建的时候,MySQL给他分配的内存大小,
类似PGA中存放数据的内存部分(不包括排序的空间)
show status like 'connections';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Connections | 80 | #接受到的来自客户端的总连接数,包括以前和现在的连接。
+---------------+-------+
show status like 'thread%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Threads_cached | 0 | #当前系统中,缓存的连接数
| Threads_connected | 1 | #当前系统中正连接的线程数
| Threads_created | 77 | #创建过的总线程数
| Threads_running | 1 |
+-------------------+-------+a.如果:
Threads_created 值过大,说明MySQL一直在创建线程,这是比较消耗资源的,应该适当增大
thread_cache_size的值
b.如果:
Threads_cached的值比参数thread_cache_size小太多,则可以适当减小thread_cache_size的值
ThreadCache命中率:
Threads_Cache_Hit=(Connections-Threads_created)/Connections*100%
一般来说,当系统稳定运行一段时间之后,我们的ThreadCache命中率应该保持在90%
左右甚至更高的比率才算正常。
7.查询缓存(Query Cache) – optional
将客户端的SQL语句(仅限select语句)通过hash计算,放在hash链表中,同时将该SQL的结果集
放在内存中cache。该hash链表中,存放了结果集的内存地址以及所涉及到的所有Table等信息。
如果与该结果集相关的任何一个表的相关信息发生变化后(包扩:数据、索引、表结构等),
就会导致结果集失效,释放与该结果集相关的所有资源,以便后面其他SQL能够使用。
当客户端有select SQL进入,先计算hash值,如果有相同的,就会直接将结果集返回。
Query Cache的负面影响:
a.使用了Query Cache后,每条select SQL都要进行hash计算,然后查找结果集。对于大量SQL
访问,会消耗过多额外的CPU。
b.如果表变更比较频繁,则会造成结果集失效率非常高。
c.结果集中保存的是整个结果,可能存在一条记录被多次cache的情况,这样会造成内存资源的
过度消耗。
Query Cache的正确使用:
a.根据表的变更情况来选择是否使用Query Cache,可使用SQL Hint:SQL_NO_CACHE和SQL_CACHE
b.对于 变更比较少 或 数据基本处于静态 的表,使用SQL_CACHE
c.对于结果集比较大的,使用Query Cache可能造成内存不足,或挤占内存。
可使用1.SQL_NO_CACHE 2.query_cache_limit控制Query Cache的最大结果集(系统默认1M)
mysql> show variables like '%query_cache%';
+------------------------------+---------+
| Variable_name | Value |
+------------------------------+---------+
| have_query_cache | YES | #是否支持Query Cache
| query_cache_limit | 1048576 | #单个结果集的最大值,默认1M
| query_cache_min_res_unit | 4096 | #每个结果集存放的最小内存,默认4K
| query_cache_size | 0 | #Query Cache总内存大小,必须是1024的整数倍
| query_cache_type | ON | #ON,OFF,DEMAND(包含SQL_CACHE的查询中才开启)
| query_cache_wlock_invalidate | OFF |
+------------------------------+---------+#query_cache_wlock_invalidate:
针对于MyISAM存储引擎,设置当有WRITELOCK在某个Table上面的时候,
读请求是要等待WRITE LOCK释放资源之后再查询还是允许直接从QueryCache中读取结果,
默认为FALSE(可以直接从QueryCache中取得结果)
mysql> show status like 'qcache%';
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| Qcache_free_blocks | 0 |
| Qcache_free_memory | 0 |
| Qcache_hits | 0 |
| Qcache_inserts | 0 |
| Qcache_lowmem_prunes | 0 |
| Qcache_not_cached | 0 |
| Qcache_queries_in_cache | 0 |
| Qcache_total_blocks | 0 |
+-------------------------+-------+# Qcache_free_blocks
QueryCache中目前还有多少剩余的blocks
a.如果Qcache_free_blocks值较大,说明Query Cache中内存碎片比较多
b.如果Qcache_free_blocks约等于Qcache_total_blocks/2,说明内存碎片非常严重
移除碎片:
flush query cache;
这个命令会把所有的存储块向上移动,并把自由块移到底部。
查询缓存碎片率:
查询缓存碎片率 = Qcache_free_blocks / Qcache_total_blocks * 100%
c.如果:
查询缓存碎片率超过20%, 可以用flush query cache整理碎片,或者减小
query_cache_min_res_unit(如果该系统的查询都是小数据量的话)
# Qcache_free_memory
QueryCache中目前剩余的内存大小
查询缓存利用率:
查询缓存利用率 = (query_cache_size – Qcache_free_memory) / query_cache_size * 100%
a.如果:
查询缓存利用率在25%以下,说明query_cache_size设置过大,可适当减小。
b.如果:
查询缓存利用率>80%,且Qcache_lowmem_prunes>50,说明query_cache_size可能有点小,或者
有太多的碎片
# Qcache_hits
Query Cache的命中次数,可以看到QueryCache的基本效果;
# Qcache_inserts
Query Cache未命中然后插入的次数
Query Cache的命中率:
=Qcache_hits/(Qcache_hits+Qcache_inserts)
# Qcache_lowmem_prunes
因为内存不足而被清除出Query Cache的SQL数量。
如果:
Qcache_lowmem_prunes的值正在增加,并且有大量的Qcache_free_blocks,
这意味着碎片导致查询正在被从缓存中永久删除。
# Qcache_not_cached
因为query_cache_type的设置或者不能被cache的select SQL数量
# Qcache_queries_in_cache
Query Cache中cache的select SQL数量
# Qcache_total_blocks
当前Query Cache中block的总数量
Query Cache限制:
- 5.1.17之前的版本不能Cache帮定变量的Query,但是从5.1.17版本开始,QueryCache已经开
始支持帮定变量的Query了;
-
所有子查询中的外部查询SQL不能被Cache;
-
在Procedure,Function以及Trigger中的Query不能被Cache;
-
包含其他很多每次执行可能得到不一样结果的函数的Query不能被Cache。
8.排序使用情况:
参数 :sort_buffer_size – 单个thread能用来排序的内存空间大小,系统默认2M
mysql> show variables like 'sort%';
+------------------+---------+
| Variable_name | Value |
+------------------+---------+
| sort_buffer_size | 2097144 |
+------------------+---------+
mysql> show global status like 'sort%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Sort_merge_passes | 0 |#在内存中无法完成排序,而在磁盘上创建临时文件的次数(两倍)
| Sort_range | 0 |#在范围内执行的排序的数量
| Sort_rows | 0 |#已经排序的行数
| Sort_scan | 0 |#通过扫描表完成的排序的数量
+-------------------+-------+9.文件打开数 open_files_limit
mysql> show variables like 'open%';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| open_files_limit | 1024 | #mysql总共能够打开的文件的数量
+------------------+-------+
mysql> show global status like 'open%file%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Open_files | 79 | # 系统当前打开的文件数
| Opened_files | 278 | # 系统打开过的文件总数
+---------------+-------+比较合适的设置:Open_files / open_files_limit * 100% <= 75%
10.表锁情况
mysql> show global status like 'table%';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| Table_locks_immediate | 96 | # 表示立即释放的表锁数
| Table_locks_waited | 0 | # 表示需要等待的表锁数
+-----------------------+-------+如果 Table_locks_immediate / Table_locks_waited > 5000,最好采用InnoDB引擎。
因为InnoDB是行锁而MyISAM是表锁,对于高并发写入的应用InnoDB效果会好些。
11.表扫描情况
mysql> show global status like 'handler_read%';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| Handler_read_first | 60 |
| Handler_read_key | 2442 |
| Handler_read_next | 286 |
| Handler_read_prev | 0 |
| Handler_read_rnd | 28 |
| Handler_read_rnd_next | 3191 |
+-----------------------+-------+
mysql> show global status like 'com_select';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Com_select | 23 |
+---------------+-------+计算表扫描率:
表扫描率 = Handler_read_rnd_next / Com_select
如果:
表扫描率超过4000,说明进行了太多表扫描,很有可能索引没有建好,
增加read_buffer_size值会有一些好处,但最好不要超过8MB。
# Handler_read_first
此选项表明SQL是在做一个全索引扫描(注意是全部,而不是部分),所以说如果存在WHERE语句,
这个值是不会变的。如果这个值的数值很大,既是好事 也是坏事。
说它好是因为毕竟查询是在索引里完成的,而不是数据文件里,说它坏是因为大数据量时,
即便是索引文件,做一次完整的扫描也是很费时的。
# Handler_read_key
此选项数值如果很高,说明系统高效的使用了索引,一切运转良好
# Handler_read_next
此选项表明在进行索引扫描时,按照索引从数据文件里取数据的次数
# Handler_read_prev
此选项表明在进行索引扫描时,按照索引倒序从数据文件里取数据的次数,
一般就是ORDER BY … DESC。
# Handler_read_rnd
简单的说,就是查询直接操作了数据文件,很多时候表现为没有使用索引或者文件排序
可能是有大量的全表扫描或连接时没恰当使用keys。
The number of requests to read a row based on a fixed position. This value is
high if you are doing a lot of queries that require sorting of the result. You
probably have a lot of queries that require MySQL to scan entire tables or you
have joins that do not use keys properly.
# Handler_read_rnd_next
此选项表明在进行数据文件扫描时,从数据文件里取数据的次数。(物理IO次数)
12.dalayed_queue_size
在被插入到实际的数据表里之前,来自insert delayed语句的数据航将在每个队列里等待
MySQL来处理他们。delayed_queue_size就是这个队列所能容纳的数据航的最大个数。当
这个队列满是,后续的insert delayed语句将被阻塞,直到这个队列里有容纳他们的空间
为止。
如果有很多客户在发出insert delayed语句以避免受阻塞,但你发现这些语句有阻塞的迹象,
加大这个变量的值将使更多的insert delayed语句更快地得到处理。
13.max_allowed_packet(最大值1G,默认值1M)
MySQL服务器在于客户端程序之间进行通信时使用的缓冲区的最大长度。
如果你的客户端经常批量传输一些非常长的语句,就需要在服务器端和客户端同时加大这个变量的值。
一般推荐,最少32M。
14.MySQL内存分配
mysql服务器为每个连接上的客户端线程,分配的内存空间:
read_buffer_size + read_rnd_buffer_size + sort_buffer_size +
thread_stack + join_buffer_size
从内存的使用方式MySQL 数据库的内存使用主要分为以下两类
· 线程独享内存
· 全局共享内存
先分析 MySQL 中主要的 “线程独享内存” 的。
在 MySQL 中,线程独享内存主要用于各客户端连接线程存储各种操作的独享数据,如线程栈信息,分组排序操作,数据读写缓冲,结果集暂存等等,而且大多数可以通过相关参数来控制内存的使用量。
线程栈信息使用内存(thread_stack):
主要用来存放每一个线程自身的标识信息,如线程id,线程运行时基本信息等等,我们可以通过 thread_stack 参数来设置为每一个线程栈分配多大的内存。
排序使用内存(sort_buffer_size):
MySQL 用此内存区域进行排序操作(filesort),完成客户端的排序请求。当我们设置的排序区缓存大小无法满足排序实际所需内存的时候,MySQL 会将数据写入磁盘文件来完成排序。由于磁盘和内存的读写性能完全不在一个数量级,所以sort_buffer_size参数对排序操作的性能影响绝对不可小视。排序操作的实现原理请参考:MySQL Order By 的实现分析(http://www.kuqin.com/database/20081206/29716.html)。
Join操作使用内存(join_buffer_size):
应用程序经常会出现一些两表(或多表)Join的操作需求,MySQL在完成某些 Join 需求的时候(all/index join),为了减少参与Join的“被驱动表”的读取次数以提高性能,需要使用到 Join Buffer 来协助完成 Join操作(具体 Join 实现算法请参考:
MySQL 中的 Join 基本实现原理(http://www.kuqin.com/database/20081206/29717.html))。当 Join Buffer 太小,MySQL 不会将该 Buffer 存入磁盘文件,而是先将Join Buffer中的结果集与需要 Join 的表进行 Join 操作,然后清空 Join Buffer 中的数据,继续将剩余的结果集写入此 Buffer 中,如此往复。这势必会造成被驱动表需要被多次读取,成倍增加 IO 访问,降低效率。
顺序读取数据缓冲区使用内存(read_buffer_size):
这部分内存主要用于当需要顺序读取数据的时候,如无法使用索引的情况下的全表扫描,全索引扫描等。在这种时候,MySQL 按照数据的存储顺序依次读取数据块,每次读取的数据快首先会暂存在read_buffer_size中,当 buffer 空间被写满或者全部数据读取结束后,再将buffer中的数据返回给上层调用者,以提高效率。
随机读取数据缓冲区使用内存(read_rnd_buffer_size):
和顺序读取相对应,当 MySQL 进行非顺序读取(随机读取)数据块的时候,会利用这个缓冲区暂存读取的数据。如根据索引信息读取表数据,根据排序后的结果集与表进行Join等等。总的来说,就是当数据块的读取需要满足一定的顺序的情况下,MySQL 就需要产生随机读取,进而使用到 read_rnd_buffer_size 参数所设置的内存缓冲区。
连接信息及返回客户端前结果集暂存使用内存(net_buffer_size):
这部分用来存放客户端连接线程的连接信息和返回客户端的结果集。当 MySQL 开始产生可以返回的结果集,会在通过网络返回给客户端请求线程之前,会先暂存在通过 net_buffer_size 所设置的缓冲区中,等满足一定大小的时候才开始向客户端发送,以提高网络传输效率。不过,net_buffer_size 参数所设置的仅仅只是该缓存区的初始化大小,MySQL 会根据实际需要自行申请更多的内存以满足需求,但最大不会超过 max_allowed_packet 参数大小。
批量插入暂存使用内存(bulk_insert_buffer_size):
当我们使用如 insert … values(…),(…),(…)… 的方式进行批量插入的时候,MySQL 会先将提交的数据放如一个缓存空间中,当该缓存空间被写满或者提交完所有数据之后,MySQL 才会一次性将该缓存空间中的数据写入数据库并清空缓存。此外,当我们进行 LOAD DATA INFILE 操作来将文本文件中的数据 Load 进数据库的时候,同样会使用到此缓冲区。
MySQL对硬件的”收益递减点“为256G内存,32CPU。
(percona-server 5.1版本)
本文转自ITPUB博客84223932的博客,原文链接:MySQL内存参数及调整,如需转载请自行联系原博主。
贴一个我目前使用的配置
Total MySQL Memory Consumption = innodb_buffer_pool_size + innodb_additional_mem_pool_size+ innodb_log_buffer_size + tmp_table_size +
(max_connections*(sort_buffer_size+read_buffer_size+join_buffer_size+binlog_cache_size))
查询现有设置
show variables like 'key_buffer_size'
show variables like 'tmp_table_size'
show variables like 'max_heap_table_size'
show variables like 'table_open_cache'
show variables like 'sort%'
show variables like 'open_files_limit%'
show variables like 'read_buffer_size%'
show global status like 'open_tables'
show global status like 'opened_tables'
show global status like 'created_tmp%'
show global status like 'thread%'
show global status like 'table%'mysql5.6, 8core16G的实例。一个我目前使用的配置。(请根据自己的实例,酌情调整)
my.cnf
[mysql]
socket=D:/vivachekcloud/mysql/data/mysql.sock
[mysqld]
lower_case_table_names=1
user= root
basedir = D:/vivachekcloud/mysql
datadir = D:/vivachekcloud/mysql/data
#log-error=D:/vivachekcloud/mysql/data/mysql.err
pid-file=D:/vivachekcloud/mysql/data/mysql.pid
socket=D:/vivachekcloud/mysql/data/mysql.sock
port = 3306
# server_id = .....
# socket = .....
# skip-grant-tables
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
# 跳过dns解析(内网没有dns)
skip-name-resolve
#Total MySQL Memory Consumption = innodb_buffer_pool_size + innodb_additional_mem_pool_size+ innodb_log_buffer_size + tmp_table_size + (max_connections*(sort_buffer_size+read_buffer_size+join_buffer_size+binlog_cache_size))
#索引缓存大小
key_buffer_size=500M
#内存中,临时表区域总大小
tmp_table_size=600M
#内存中,单个临时表的最大值,超过的部分会放到硬盘上
max_heap_table_size=300M
#单个thread能用来排序的内存空间大小,系统默认2M
sort_buffer_size=600M
#Join操作使用内存
join_buffer_size=600M
#顺序读取数据缓冲区使用内存
read_buffer_size=8M
#随机读取数据缓冲区使用内存
read_rnd_buffer_size=8M
#用于缓存索引和数据的内存大小,这个当然是越多越好, 数据读写在内存中非常快, 减少了对磁盘的读写。 当数据提交或满足检查点条件后才一次性将内存数据刷新到磁盘中。
# 然而内存还有操作系统或数据库其他进程使用, 根据经验,推荐设置innodb-buffer-pool-size为服务器总可用内存的75%。 若设置不当, 内存使用可能浪费或者使用过多。 对于繁忙的服务器, buffer pool 将划分为多个实例以提高系统并发性, 减少线程间读写缓存的争用。buffer pool 的大小首先受 innodb_buffer_pool_instances 影响, 当然影响较小。
innodb_buffer_pool_size=8GMySQL性能的五大配置参数(内存参数)以及mysql内存占用过多优化
转载来源: https://www.modb.pro/db/55592
内存参数:
存储引擎/共享 日志缓冲区,缓冲区池
innodb_buffer_pool_size innodb_additional_mem_pool_size innodb_log_buffer_size
服务器/共享 查询调整缓存 线程高速络缓存
query_cache table_cahce table_definition_cache
连接/会话 排序缓冲区,读取缓冲区,临时表
binlog_cache_size read_buffer_size read_rnd_buffer_size join_buffer_size sort_buffer_size tmp_table_size thread_cache_size bulk_insert_buffer_size net_buffer_length thread_stack
下面转载自:http://www.bitscn.com/pdb/mysql/201405/227583.html
*.线程独享内存 *.全局共享内存 全局共享内存类似ORACLE的系统全局区SGA,线程独享内存类似ORACLE的进程全局区PGA
一、线程独享内存
在MySQL中,线程独享内存主要用于各客户端连接线程存储各种操作的独享数据,如线程栈信息,分组排序操作,数据读写缓冲,结果集暂存等等,而且大多数可以通过相关参数来控制内存的使用量。
* 线程栈信息使用内存(thread_stack): 主要用来存放每一个线程自身的标识信息,如线程id,线程运行时基本信息等等,我们可以通过 thread_stack 参数来设置为每一个线程栈分配多大的内存。 Global,No Dynamic,Default 192K(32bit), 256K(32bit), 推荐配置:默认
* 排序使用内存(sort_buffer_size): MySQL 用此内存区域进行排序操作(filesort),完成客户端的排序请求。当我们设置的排序区缓存大小无法满足排序实际所需内存的时候,MySQL会将数据写入磁盘文件来完成排序。由于磁盘和内存的读写性能完全不在一个数量级, 所以sort_buffer_size参数对排序操作的性能影响绝对不可小视。排序操作的实现原理请参考:MySQL Order By的实现分析。 什么时候会用到? 对结果集排序时 使用确认: 可以通过查询计划中的Extra列的值为Using file-sort来证实使用了和这个缓冲区。 >explain select * from user1; Global Session,Dynamic,Default 2M(32bit), 2M(32bit), 推荐配置:8M(内存足够的情况下),默认(内存紧张的情况) 优化建议:一种说法是增大可以提高order by,group by性能,防止数据写入磁盘占用IO资源,还有一种说法是不推荐增加这个缓冲区的大小,理由是当值太大时可能会降低查询的执行速度。目前我没有实验证实。
* Join操作使用内存(join_buffer_size): 应用程序经常会出现一些两表(或多表)Join的操作需求,MySQL在完成某些Join需求的时候(all/index join),为了减少参与Join的“被驱动表”的读取次数以提高性能,需要使用到Join Buffer来协助完成Join操作 (具体Join实现算法请参考:MySQL中的 Join 基本实现原理)。当Join Buffer太小,MySQL 不会将该Buffer存入磁盘文件,而是先将Join Buffer中的结果集与需要Join的表进行Join操作,然后清空Join Buffer中的数据, 继续将剩余的结果集写入此Buffer中,如此往复。这势必会造成被驱动表需要被多次读取,成倍增加IO访问,降低效率。 什么时候会用到? 当查询必须连接两个表(或多个)的数据集并且不能使用索引时,这个缓冲区会被用到。这个缓冲区专门为每个线程的无索引链接操作准备的。 使用确认: 可以通过查询计划中的Extra列的值为Using join bufer来证实使用了和这个缓冲区。 >explain select * from user1; +——+————-+——-+——-+—————+——+———+——+——+————-+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +——+————-+——-+——-+—————+——+———+——+——+————-+ | 1 | SIMPLE | user1 | index | NULL | name | 78 | NULL | 3 | Using index | +——+————-+——-+——-+—————+——+———+——+——+————-+ Global Session,Dynamic,Default 128K 各版本平台最大值不一样 推荐配置:8M(内存足够的情况下),默认(内存紧张的情况) 优化建议:有一种说法是增加这个缓冲区的大小不会加快全连接操作的速度。目前我没有实验证实。
* 顺序读取数据缓冲区使用内存(read_buffer_size): 这部分内存主要用于当需要顺序读取数据的时候,如无法使用索引的情况下的全表扫描,全索引扫描等。在这种时候,MySQL按照数据的存储顺序依次读取数据块,每次读取的数据快首先会暂存在read_buffer_size中, 当buffer空间被写满或者全部数据读取结束后,再将buffer中的数据返回给上层调用者,以提高效率。 Global Session,Dynamic,Default 128K 推荐配置:4M/8M
* 随机读取数据缓冲区使用内存(read_rnd_buffer_size): 和顺序读取相反,当MySQL进行非顺序读取(随机读取)数据块的时候,会利用这个缓冲区暂存读取的数据。如根据索引信息读取表数据,根据排序后的结果集与表进行Join等等。 总的来说,就是当数据块的读取需要满足一定的顺序的情况下,MySQL就需要产生随机读取,进而使用到read_rnd_buffer_size 参数所设置的内存缓冲区。 Global Session,Dynamic,Default 256K 推荐配置:8M
* 连接信息及返回客户端前结果集暂存使用内存(net_buffer_lenth): 这部分用来存放客户端连接线程的连接信息和返回客户端的结果集。当MySQL开始产生可以返回的结果集,会在通过网络返回给客户端请求线程之前,会先暂存在通过net_buffer_lenth所设置的缓冲区中, 等满足一定大小的时候才开始向客户端发送,以提高网络传输效率。不过net_buffer_lenth参数所设置的仅仅只是该缓存区的初始化大小,MySQL会根据实际需要自行申请更多的内存以满足需求, 但最大不会超过 max_allowed_packet 参数大小。 Global Session,Dynamic,Default 16K 推荐配置:默认 16K
* 批量插入暂存使用内存(bulk_insert_buffer_size): 当我们使用如 insert … values(…),(…),(…)… 的方式进行批量插入的时候,MySQL会先将提交的数据放如一个缓存空间中,当该缓存空间被写满或者提交完所有数据之后,MySQL才会一次性将该缓存空间中的数据写入数据库并清空缓存。 此外,当我们进行 LOAD DATA INFILE操作来将文本文件中的数据Load进数据库的时候,同样会使用到此缓冲区。 Global Session,Dynamic,Default 8M 推荐配置:默认 8M * 临时表使用内存(tmp_table_size): 当我们进行一些特殊操作如需要使用临时表才能完成的Order By,Group By 等等,MySQL可能需要使用到临时表。当我们的临时表较小(小于tmp_table_size 参数所设置的大小)的时候,MySQL会将临时表创建成内存临时表, 只有当tmp_table_size所设置的大小无法装下整个临时表的时候,MySQL才会将该表创建成MyISAM存储引擎的表存放在磁盘上。不过,当另一个系统参数 max_heap_table_size 的大小还小于 tmp_table_size 的时候, MySQL将使用 max_heap_table_size 参数所设置大小作为最大的内存临时表大小,而忽略tmp_table_size 所设置的值。而且 tmp_table_size 参数从 MySQL 5.1.2 才开始有,之前一直使用 max_heap_table_size。 谁小谁生效.另外还有一个参数max_tmp_tables,没有使用 tmp_table_size Global Session,Dynamic,Default 16M 推荐配置:64M max_heap_table_size Global Session,Dynamic,Default 8M This variable sets the maximum size to which user-created MEMORY tables are permitted to grow 这个变量定义了MEMORY存储引擎表的最大容量。 This variable is also used in conjunction with tmp_table_size to limit the size of internal in-memory tables. See 这个变量也与tmp_table_size一起使用限制内部内存表的大小。请见 http://dev.mysql.com/doc/refman/5.5/en/internal-temporary-tables.html 推荐配置:64M 主要根据业务以及服务器内存来调整,如果有需要到则可以调整到。GB居然使用2G的配置,汗
目前没有一个简便的方式来确定内部临时表的总容量。可以通过MySQL状态变量created_tmp_tables和created_tmp_disk_tables来确定创建了临时表和基于磁盘的临时表 mysql> show global status like ‘create%tables’; +————————-+——-+ | Variable_name | Value | +————————-+——-+ | Created_tmp_disk_tables | 0 | | Created_tmp_tables | 0 | +————————-+——-+ 5.5中,可以使用PERFORMANCE—SCHEMA来帮助统计基于磁盘的临时表的总大小
补充说明:上面所列举的MySQL线程独享内存仅仅只是所有线程独享内存中的部分,并不是全部,只是这些可能对MySQL的性能产生较大的影响,且可以通过系统参数进行调节。 由于以上内存都是线程独享,极端情况下的内存总体使用量将是所有连接线程的总倍数。所以在设置过程中一定要谨慎,切不可为了提升性能就盲目的增大各参数值, 避免因为内存不够而产生Out Of Memory异常或者是严重的Swap交换反而降低整体性能。
二、全局共享内存
全局共享内则主要是MySQL Instance以及底层存储引擎用来暂存各种全局运算及可共享的暂存信息,如 存储查询缓存的 Query Cache, 缓存连接线程的 Thread Cache, 缓存表文件句柄信息的 Table Cache, 缓存二进制日志的 BinLog Buffer, 缓存MyISAM存储引擎索引键的 Key Buffer 存储InnoDB数据和索引的 InnoDB Buffer Pool 等等。下面针对 MySQL 主要的共享内存进行一个简单的分析。
* MyISAM索引缓存 Key Buffer(key_buffer_size): MyISAM 索引缓存将MyISAM表的索引信息(.MYI文件)缓存在内存中,以提高其访问性能。这个缓存可以说是影响MyISAM存储引擎性能的最重要因素之一了,通过 key_buffere_size 设置可以使用的最大内存空间。 注意:即使运行一个全部采用innodb的模式,仍需要定义一个索引码缓冲区,因为MYSQL元信息与MyISAM定义相同。 Global ,Dynamic,Default 8M 推荐配置:默认 8M 如何确认key_buffer_size不够用? 使用show full proceslist的State列中,值Repairing the keycache是一个明显的指标,它指出当前索引码缓冲区大小不足以执行当前运行的SQL语句。这将导致额外的磁盘I/O开销。
* 查询缓存 Query Cache (query_cache_size): http://dev.mysql.com/doc/refman/5.5/en/query-cache-configuration.html http://dev.mysql.com/doc/refman/5.5/en/query-cache-status-and-maintenance.html 查询缓存是MySQL比较独特的一个缓存区域,用来缓存特定Query的结果集(Result Set)信息,且共享给所有客户端。通过对Query语句进行特定的Hash计算之后与结果集对应存放在Query Cache中,以提高完全相同的Query语句的相应速度。 当我们打开MySQL的Query Cache之后,MySQL接收到每一个SELECT类型的Query之后都会首先通过固定的Hash算法得到该Query的Hash值,然后到Query Cache中查找是否有对应的Query Cache。如果有,则直接将Cache的结果集返回给客户端。 如果没有,再进行后续操作,得到对应的结果集之后将该结果集缓存到Query Cache中,再返回给客户端。当任何一个表的数据发生任何变化之后,与该表相关的所有Query Cache全部会失效,所以Query Cache对变更比较频繁的表并不是非常适用, 但对那些变更较少的表是非常合适的,可以极大程度的提高查询效率,如那些静态资源表,配置表等等。为了尽可能高效的利用Query Cache,MySQL针对Query Cache设计了多个query_cache_type值 和两个Query Hint:SQL_CACHE和SQL_NO_CACHE。当query_cache_type设置为0(或者 OFF)的时候不使用Query Cache,当设置为1(或者 ON)的时候,当且仅当Query中使用了SQL_NO_CACHE 的时候MySQL会忽略Query Cache, 当query_cache_type设置为2(或者DEMAND)的时候,当且仅当Query中使用了SQL_CACHE提示之后,MySQL才会针对该Query使用Query Cache。可以通过query_cache_size来设置可以使用的最大内存空间。 Global Dynamic,Default 0 推荐配置:16M 如何确定系统query cache的情况? show global status like ‘Qcache%’;或者 select * from information_schema.GLOBAL_STATUS where VARIABLE_NAME like ‘Qcache%’; 公式: (Qcache_hits/Qcache_hits+Com_select+1)*100来确定查询缓存的有效性 mysql> show variables like ‘query_cache_size’; +——————+———-+ | Variable_name | Value | +——————+———-+ | query_cache_size | 16777216 | +——————+———-+ 1 row in set (0.00 sec) mysql> show global status like ‘Qcache%’; +————————-+————+ | Variable_name | Value | +————————-+————+ | Qcache_free_blocks | 535 | | Qcache_free_memory | 4885448 | | Qcache_hits | 1858574835 | | Qcache_inserts | 1619931831 | | Qcache_lowmem_prunes | 802889469 | | Qcache_not_cached | 825000679 | | Qcache_queries_in_cache | 4411 | | Qcache_total_blocks | 9554 | +————————-+————+ 8 rows in set (0.00 sec) mysql> show global status like ‘Com_select’; +—————+————+ | Variable_name | Value | +—————+————+ | Com_select | 2445037535 | +—————+————+ 1 row in set (0.00 sec)
* 连接线程缓存 Thread Cache(thread_cache_size): 连接线程是MySQL为了提高创建连接线程的效率,将部分空闲的连接线程保持在一个缓存区以备新进连接请求的时候使用,这尤其对那些使用短连接的应用程序来说可以极大的提高创建连接的效率。 当我们通过thread_cache_size设置了连接线程缓存池可以缓存的连接线程的大小之后,可以通过(Connections – Threads_created) Connections * 100% 计算出连接线程缓存的命中率。 注意,这里设置的是可以缓存的连接线程的数目,而不是内存空间的大小。 Global,Dynamic,Default 0 推荐配置:8个 如何确定系统Thread Cache的情况? mysql> show global status like ‘Threads_created’; +—————–+——-+ | Variable_name | Value | +—————–+——-+ | Threads_created | 506 | +—————–+——-+ 1 row in set (0.00 sec)
mysql> show global status like ‘connections’; +—————+———-+ | Variable_name | Value | +—————+———-+ | Connections | 16513711 | +—————+———-+ 1 row in set (0.00 sec) 16513711-506/16513711 * 100% =99.9938% 很高的命中率啊 这台之只读的slave
* 表缓存 Table Cache(table_open_cache): 表缓存区主要用来缓存表文件的文件句柄信息,在 MySQL5.1.3之前的版本通过table_cache参数设置,但从MySQL5.1.3开始改为table_open_cache来设置其大小。当我们的客户端程序提交Query给MySQL的时候, MySQL需要对Query所涉及到的每一个表都取得一个表文件句柄信息,如果没有Table Cache,那么MySQL就不得不频繁的进行打开关闭文件操作,无疑会对系统性能产生一定的影响,Table Cache 正是为了解决这一问题而产生的。 在有了Table Cache之后,MySQL每次需要获取某个表文件的句柄信息的时候,首先会到Table Cache中查找是否存在空闲状态的表文件句柄。如果有,则取出直接使用,没有的话就只能进行打开文件操作获得文件句柄信息。 在使用完之后,MySQL会将该文件句柄信息再放回Table Cache 池中,以供其他线程使用。注意,这里设置的是可以缓存的表文件句柄信息的数目,而不是内存空间的大小。 Global,Dynamic,Default 400 推荐配置:根据内存配置4G 2048 大于最大Opened_tables 如何确定系统table_open_cache的情况? mysql> show variables like ‘table_open_cache’; +——————+——-+ | Variable_name | Value | +——————+——-+ | table_open_cache | 512 | +——————+——-+ 1 row in set (0.00 sec) mysql> show global status like ‘open%_tables’; +—————+——-+ | Variable_name | Value | +—————+——-+ | Open_tables | 512 | | Opened_tables | 6841 | +—————+——-+ 2 rows in set (0.00 sec) 调优参考: http://blog.zfcms.com/article/282 http://www.kuqin.com/database/20120815/328904.html 两个参数的值。其中Open_tables是当前正在打开表的数量,Opened_tables是所有已经打开表的数量。 如果Open_tables的值已经接近table_cache的值,且Opened_tables还在不断变大,则说明mysql正在将缓存的表释放以容纳新的表,此时可能需要加大table_cache的值。对于大多数情况,比较适合的值: Open_tables Opened_tables >= 0.85 Open_tables table_cache <= 0.95 如果对此参数的把握不是很准,VPS管理百科给出一个很保守的设置建议:把MySQL数据库放在生产环境中试运行一段时间,然后把参数的值调整得比Opened_tables的数值大一些,并且保证在比较高负载的极端条件下依然比Opened_tables略大。 在mysql默认安装情况下,table_cache的值在2G内存以下的机器中的值默认时256到 512,如果机器有4G内存,则默认这个值是2048,
* 表定义信息缓存 Table definition Cache (table_definition_cache): 表定义信息缓存是从 MySQL5.1.3 版本才开始引入的一个新的缓存区,用来存放表定义信息。当我们的 MySQL 中使用了较多的表的时候,此缓存无疑会提高对表定义信息的访问效率。 MySQL 提供了 table_definition_cache 参数给我们设置可以缓存的表的数量。注意,这里设置的是可以缓存的表定义信息的数目,而不是内存空间的大小。 The number of table definitions (from .frm files) that can be stored in the definition cache. If you use a large number of tables, you can create a large table definition cache to speed up opening of tables. Global, Dynamic, Default 400 推荐配置:根据内存配置4G 2048 和Table Cache一样即可
* 二进制日志缓冲区Binlog Cache( binlog_cache_size): 二进制日志缓冲区主要用来缓存由于各种数据变更操做所产生的 Binary Log 信息。为了提高系统的性能,MySQL 并不是每次都是将二进制日志直接写入 Log File,而是先将信息写入 Binlog Buffer 中, 当满足某些特定的条件(如 sync_binlog参数设置)之后再一次写入 Log File 中。我们可以通过 binlog_cache_size 来设置其可以使用的内存大小,同时通过 max_binlog_cache_size 限制其最大大小 (当单个事务过大的时候 MySQL 会申请更多的内存)。当所需内存大于 max_binlog_cache_size 参数设置的时候,MySQL 会报错:“Multi-statement transaction required more than ‘max_binlog_cache_size’ bytes of storage”。 Global,Dynamic,Default 32K 推荐配置:2M
* InnoDB 日志缓冲区 InnoDB Log Buffer (innodb_log_buffer_size): 这是 InnoDB 存储引擎的事务日志所使用的缓冲区。类似于 Binlog Buffer,InnoDB 在写事务日志的时候,为了提高性能,也是先将信息写入 Innofb Log Buffer 中,当满足 innodb_flush_log_trx_commit 参数所设置的相应条件(或者日志缓冲区写满)之后,才会将日志写到文件(或者同步到磁盘)中。可以通过 innodb_log_buffer_size 参数设置其可以使用的最大内存空间。 注:innodb_flush_log_trx_commit 参数对 InnoDB Log 的写入性能有非常关键的影响。该参数可以设置为0,1,2,解释如下:
0:log buffer中的数据将以每秒一次的频率写入到log file中,且同时会进行文件系统到磁盘的同步操作,但是每个事务的commit并不会触发任何log buffer 到log file的刷新或者文件系统到磁盘的刷新操作; 1:在每次事务提交的时候将log buffer 中的数据都会写入到log file,同时也会触发文件系统到磁盘的同步; 2:事务提交会触发log buffer 到log file的刷新,但并不会触发磁盘文件系统到磁盘的同步。此外,每秒会有一次文件系统到磁盘同步操作。 此外,MySQL文档中还提到,这几种设置中的每秒同步一次的机制,可能并不会完全确保非常准确的每秒就一定会发生同步,还取决于进程调度的问题。实际上,InnoDB 能否真正满足此参数所设置值代表的意义正常 Recovery 还是受到了不同 OS 下文件系统以及磁盘本身的限制,可能有些时候在并没有真正完成磁盘同步的情况下也会告诉 mysqld 已经完成了磁盘同步。
Global,Dynamic,Default 8M 推荐配置:8M 默认
* InnoDB 数据和索引缓存 InnoDB Buffer Pool(innodb_buffer_pool_size): InnoDB Buffer Pool 对 InnoDB 存储引擎的作用类似于 Key Buffer Cache 对 MyISAM 存储引擎的影响,主要的不同在于 InnoDB Buffer Pool 不仅仅缓存索引数据,还会缓存表的数据, 而且完全按照数据文件中的数据快结构信息来缓存,这一点和 Oracle SGA 中的 database buffer cache 非常类似。所以,InnoDB Buffer Pool 对 InnoDB 存储引擎的性能影响之大就可想而知了。 可以通过 (Innodb_buffer_pool_read_requests – Innodb_buffer_pool_reads) Innodb_buffer_pool_read_requests * 100% 计算得到 InnoDB Buffer Pool 的命中率。 global级别,不可动态变更 Default 128M 设置InnoDB数据和索引内存缓存空间大小 配置方式:配置文件中配置 选择参数:50 – 80 % RAM
mysql> show variables like ‘%innodb_buffer%’; +——————————+———–+ | Variable_name | Value | +——————————+———–+ | innodb_buffer_pool_instances | 1 | | innodb_buffer_pool_size | 268435456 | +——————————+———–+ 2 rows in set (0.00 sec) 通过show global status和show engine innodb status/G的BUFFER POOL AND MEMORY mysql> show global status like ‘%innodb_buffer%’; +—————————————+————–+ | Variable_name | Value | +—————————————+————–+ | Innodb_buffer_pool_pages_data | 15684 | | Innodb_buffer_pool_bytes_data | 256966656 | | Innodb_buffer_pool_pages_dirty | 210 | | Innodb_buffer_pool_bytes_dirty | 3440640 | | Innodb_buffer_pool_pages_flushed | 372378403 | | Innodb_buffer_pool_pages_free | 1 | | Innodb_buffer_pool_pages_misc | 698 | | Innodb_buffer_pool_pages_total | 16383 | | Innodb_buffer_pool_read_ahead_rnd | 0 | | Innodb_buffer_pool_read_ahead | 691803 | | Innodb_buffer_pool_read_ahead_evicted | 41350 | | Innodb_buffer_pool_read_requests | 170965099291 | | Innodb_buffer_pool_reads | 5392513 | | Innodb_buffer_pool_wait_free | 0 | | Innodb_buffer_pool_write_requests | 5825388207 | +—————————————+————–+ 15 rows in set (0.01 sec)
mysql> show engine innodb status/G BUFFER POOL AND MEMORY -——————— Total memory allocated 274726912; in additional pool allocated 0 Dictionary memory allocated 4055091 Buffer pool size 16383 Free buffers 1 Database pages 15673 Old database pages 5765 Modified db pages 521 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 27497746, not young 0 0.00 youngs/s, 0.00 non-youngs/s Pages read 6346456, created 1902566, written 372381712 0.00 reads/s, 0.37 creates/s, 27.75 writes/s Buffer pool hit rate 1000 1000, young-making rate 0 1000 not 0 1000 Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 15673, unzip_LRU len: 0 I/O sum[1107]:cur[0], unzip sum[0]:cur[0] 命中率 Innodb_buffer_pool_read_requests – Innodb_buffer_pool_reads) Innodb_buffer_pool_read_requests * 100% 170965099291-5392513/170965099291 × 100% = 99.99%
* InnoDB 字典信息缓存 InnoDB Additional Memory Pool(innodb_additional_mem_pool_size): InnoDB 字典信息缓存主要用来存放 InnoDB 存储引擎的字典信息以及一些 internal 的共享数据结构信息。所以其大小也与系统中所使用的 InnoDB 存储引擎表的数量有较大关系。不过,如果我们通过 innodb_additional_mem_pool_size 参数所设置的内存大小不够,InnoDB 会自动申请更多的内存,并在 MySQL 的 Error Log 中记录警告信息。 global级别,不可动态变更 Default 8M 设置InnoDB存放数据库字典信息的Buffer大小 推荐配置:50M
三、查看统计
1.查看各参数内存配置方式 #全局共享内存 9个变量 show variables like ‘innodb_buffer_pool_size’; * InnoDB 数据和索引缓存(InnoDB Buffer Pool) / show variables like ‘innodb_additional_mem_pool_size’; * InnoDB 字典信息缓存(InnoDB Additional Memory Pool)/ show variables like ‘innodb_log_buffer_size’; * InnoDB 日志缓冲区(InnoDB Log Buffer) / show variables like ‘binlog_cache_size’; / 二进制日志缓冲区(Binlog Buffer)/ show variables like ‘thread_cache_size’; / 连接线程缓存(Thread Cache)/ show variables like ‘query_cache_size’; / 查询缓存(Query Cache)/ show variables like ‘table_open_cache’; / 表缓存(Table Cache) / show variables like ‘table_definition_cache’; / 表定义信息缓存(Table definition Cache) / show variables like ‘key_buffer_size’; / MyISAM索引缓存(Key Buffer) / #最大线程数 show variables like ‘max_connections’; #线程独享内存 6个变量 show variables like ‘thread_stack’; / 线线程栈信息使用内存(thread_stack) / show variables like ‘sort_buffer_size’; / 排序使用内存(sort_buffer_size) / show variables like ‘join_buffer_size’; / Join操作使用内存(join_buffer_size) / show variables like ‘read_buffer_size’; / 顺序读取数据缓冲区使用内存(read_buffer_size) / show variables like ‘read_rnd_buffer_size’; / 随机读取数据缓冲区使用内存(read_rnd_buffer_size) / show variables like ‘tmp_table_size’; / 临时表使用内存(tmp_table_size) ,我实际计算把tmp_table_size放入全局共享内*/ 也可以通过系统变量的方式直接获取 select @@key_buffer_size; select @@max_connections
2.mysql内存计算公式 mysql使用的内存 = 全局共享内存+最大线程数×线程独享内存 mysql used mem=innodb_buffer_pool_size+innodb_additional_mem_pool_size+innodb_log_buffer_size+binlog_cache_size+thread_cache_size+query_cache_size+table_open_cache+table_definition_cache+key_buffer_size +max_connections*( thread_stack+sort_buffer_size+join_buffer_size+read_buffer_size+read_rnd_buffer_size+tmp_table_size)
SET @kilo_bytes=1024; SET @mega_bytes=@kilo_bytes1024; SET @giga_bytes=@mega_bytes1024; SELECT (@@innodb_buffer_pool_size+@@innodb_additional_mem_pool_size+@@innodb_log_buffer_size+@@binlog_cache_size+@@thread_cache_size+@@query_cache_size+@@table_open_cache+@@table_definition_cache+@@key_buffer_size+@@max_connections*(@@thread_stack+@@sort_buffer_size+@@join_buffer_size+@@read_buffer_size+@@read_rnd_buffer_size+@@tmp_table_size))/@giga_bytes AS MAX_MEMORY_GB; 结果不要超过总内存,其他的看慢SQL 日志,慢慢调优
这个理论最大的内存使用量,在5.5版本中tmp_table_size默认是16M,按默认u自大连接数151计算,光线程独享的临时表占据的空间都是2416M,我实际计算把tmp_table_size放入全局共享内 我的计算公式 mysql使用的内存 = 全局共享内存+最大线程数×线程独享内存 mysql used mem=innodb_buffer_pool_size+innodb_additional_mem_pool_size+innodb_log_buffer_size+binlog_cache_size+thread_cache_size+query_cache_size+table_open_cache+table_definition_cache+key_buffer_size+tmp_table_size +max_connections*( thread_stack+sort_buffer_size+join_buffer_size+read_buffer_size+read_rnd_buffer_size)
链接:
https://blog.csdn.net/miyatang/article/details/54881547
https://www.cnblogs.com/heruiguo/p/12603825.html
最近在通过程序从mysql的数据局抽取到mongodb过程中发现mysql所在的服务器内存直接爆了。通过top发现内存占用最高的进程就是mysql

于是开始按照以下步骤排查:
(1).查看mysql里的线程,观察是否有长期运行或阻塞的sql:
show full processlist
经查看,没有发现相关线程,可排除该原因
(2).疑似mysql连接使用完成后没有真正释放内存,查看mysql内存,缓存的相关配置,使用如
show global variables like ‘%sort_buffer_size%’;
查看相关的配置项,结果列表汇总如下
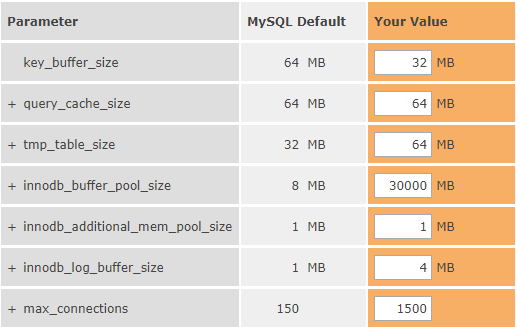
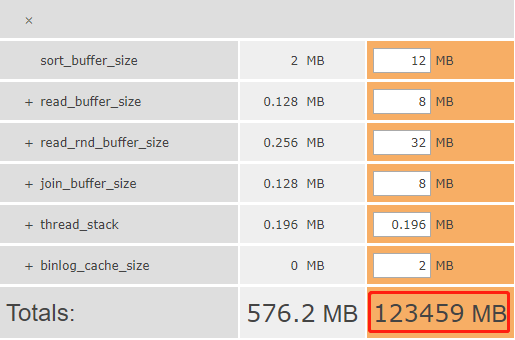
( 注:上图为mysql使用内存计算器,具体地址为http://www.mysqlcalculator.com/ )
只需把你的my.conf配置参数填上去就可以计算mysql占用的内存大小,我的计算结果为123459M,120G的内存,但是我的物理机总的内存188G
由于该机器还有其他业务运行,显然这个参数不合理,需要调整
(3).其中
key_buffer_size = 32M //key_buffer_size指定索引缓冲区的大小,它决定索引处理的速度,尤其是索引读的速度。只对MyISAM表起作用。即使你不使用MyISAM表,但是内部的临时磁盘表是MyISAM表,也要使用该值。由于我的数据库引擎为innodb,大部分表均为innodb,此处取默认值一半32M。
query_cache_size = 64M //查询缓存大小,当打开时候,执行查询语句会进行缓存,读写都会带来额外的内存消耗,下次再次查询若命中该缓存会立刻返回结果。默认改选项为关闭,打开则需要调整参数项query_cache_type=ON。此处采用默认值64M。
tmp_table_size = 64M //范围设置为64-256M最佳,当需要做类似group by操作生成的临时表大小,提高联接查询速度的效果,调整该值直到created_tmp_disk_tables / created_tmp_tables * 100% <= 25%,处于这样一个状态之下,效果较好,如果网站大部分为静态内容,可设置为64M,如果为动态页面,则设置为100M以上,不宜过大,导致内存不足I/O堵塞。此处我们设置为64M。
innodb_buffer_pool_size = 8196M //这个参数主要作用是缓存innodb表的索引,数据,插入数据时的缓冲。专用mysql服务器设置的大小: 操作系统内存的70%-80%最佳。由于我们的服务器还部署有其他应用,估此处设置为8G。此外,这个参数是非动态的,要修改这个值,需要重启mysqld服务。设置的过大,会导致system的swap空间被占用,导致操作系统变慢,从而减低sql查询的效率。
innodb_additional_mem_pool_size = 16M //用来存放Innodb的内部目录,这个值不用分配太大,系统可以自动调。不用设置太高。通常比较大数据设置16M够用了,如果表比较多,可以适当的增大。如果这个值自动增加,会在error log有中显示的。此处我们设置为16M。
innodb_log_buffer_size = 8M //InnoDB的写操作,将数据写入到内存中的日志缓存中,由于InnoDB在事务提交前,并不将改变的日志写入到磁盘中,因此在大事务中,可以减轻磁盘I/O的压力。通常情况下,如果不是写入大量的超大二进制数据(a lot of huge blobs),4MB-8MB已经足够了。此处我们设置为8M。
max_connections = 800 //最大连接数,根据同时在线人数设置一个比较综合的数字,最大不超过16384。此处我们根据系统使用量综合评估,设置为800。
sort_buffer_size = 2M //是一个connection级参数,在每个connection第一次需要使用这个buffer的时候,一次性分配设置的内存。并不是越大越好,由于是connection级的参数,过大的设置+高并发可能会耗尽系统内存资源。官方文档推荐范围为256KB~2MB,这里我们设置为2M。
read_buffer_size = 2M //(数据文件存储顺序)是MySQL读入缓冲区的大小,将对表进行顺序扫描的请求将分配一个读入缓冲区,MySQL会为它分配一段内存缓冲区,read_buffer_size变量控制这一缓冲区的大小,如果对表的顺序扫描非常频繁,并你认为频繁扫描进行的太慢,可以通过增加该变量值以及内存缓冲区大小提高其性能,read_buffer_size变量控制这一提高表的顺序扫描的效率 数据文件顺序。此处我们设置得比默认值大一点,为2M。
read_rnd_buffer_size = 250K //是MySQL的随机读缓冲区大小,当按任意顺序读取行时(列如按照排序顺序)将分配一个随机读取缓冲区,进行排序查询时,MySQL会首先扫描一遍该缓冲,以避免磁盘搜索,提高查询速度,如果需要大量数据可适当的调整该值,但MySQL会为每个客户连接分配该缓冲区所以尽量适当设置该值,以免内存开销过大。表的随机的顺序缓冲 提高读取的效率。此处设置为跟默认值相似,250KB。
join_buffer_size = 250K //多表参与join操作时的分配缓存,适当分配,降低内存消耗,此处我们设置为250KB。
thread_stack = 256K //每个连接线程被创建时,MySQL给它分配的内存大小。当MySQL创建一个新的连接线程时,需要给它分配一定大小的内存堆栈空间,以便存放客户端的请求的Query及自身的各种状态和处理信息。Thread Cache 命中率:Thread_Cache_Hit = (Connections – Threads_created) / Connections * 100%;命中率处于90%才算正常配置,当出现“mysql-debug: Thread stack overrun”的错误提示的时候需要增加该值。此处我们配置为256K。
binlog_cache_size = 250K // 为每个session 分配的内存,在事务过程中用来存储二进制日志的缓存。作用是提高记录bin-log的效率。没有什么大事务,dml也不是很频繁的情况下可以设置小一点,如果事务大而且多,dml操作也频繁,则可以适当的调大一点。前者建议是1048576 –1M;后者建议是: 2097152 – 4194304 即 2–4M。此处我们根据系统实际,配置为250KB。
调整后各项性能参数如下图,且经过图表计算,实例使用的内存将稳定在12G左右,符合当前系统负载情况
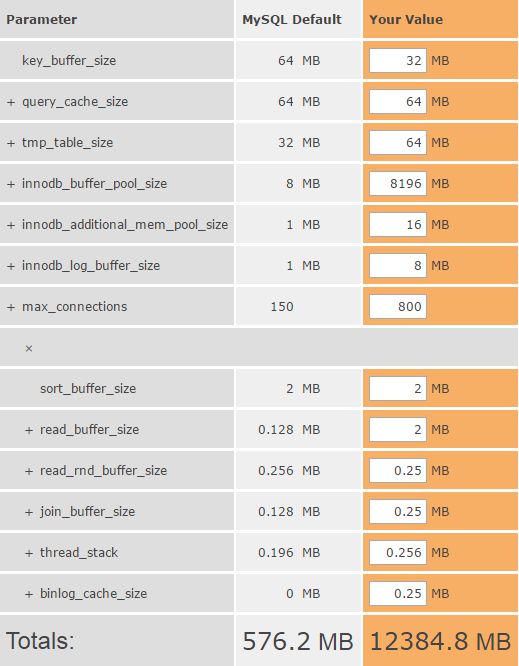
之后重启Mysql实例,发现内存占用量回落,并且长时间内没有再次发生占用过高情况,优化成功。
作者:凉生墨客 本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
https://www.cnblogs.com/heruiguo/p/12603825.html
https://www.cnbugs.com/post-3462.html
发表回复