C程序的编译与链接过程
C语言写的代码,要想变成可执行程序,需要经过编译、链接两个过程。(C语言是编译型语言)
C语言应用程序的开发,现在大部分都是在IDE(集成开发环境)中完成的:新建项目,编写代码,点击调试或运行按钮。
点击调试或运行时,隐式做了源代码编译(+汇编)为目标文件,再链接为可执行文件,最后再帮我们加载到操作系统中运行。
编译与链接
(以下来源于知乎海枫的回答)
以一个简单的例子引入,各位请看以下代码:
#include <stdio.h>
void print_banner()
{
printf("Welcome to World of PLT and GOT\n");
}
int main(void)
{
print_banner();
return 0;
}编译:
gcc -Wall -g -o test.o -c test.c -m32
链接:
gcc -o test test.o -m32
注意:现代Linux系统都是x86_64系统了,后面需要对中间文件test.o以及可执行文件test反编译,分析汇编指令,因此在这里使用-m32选项生成i386架构指令而非x86_64架构指令。
经编译和链接阶段之后,test可执行文件中print_banner函数的汇编指令会是怎样的呢?我猜应该与下面的汇编类似:
080483cc <print_banner>:
80483cc: push %ebp
80483cd: mov %esp, %ebp
80483cf: sub $0x8, %esp
80483d2: sub $0xc, %esp
80483d5: push $0x80484a8
80483da: call **<printf函数的地址>**
80483df: add $0x10, %esp
80483e2: nop
80483e3: leave
80483e4: retprint_banner函数内调用了printf函数,而printf函数位于glibc动态库内,所以在编译和链接阶段,链接器无法知知道进程运行起来之后printf函数的加载地址。故上述的****<printf函数地址>**** 一项是无法填充的,只有进程运运行后,printf函数的地址才能确定。
那么问题来了:进程运行起来之后,glibc动态库也装载了,printf函数地址亦已确定,上述call指令如何修改(重定位)呢?
一个简单的方法就是将指令中的****<printf函数地址>****修改printf函数的真正地址即可。
但这个方案面临两个问题:
- 现代操作系统不允许修改代码段,只能修改数据段
- 如果print_banner函数是在一个动态库(.so对象)内,修改了代码段,那么它就无法做到系统内所有进程共享同一个动态库。
因此,printf函数地址只能回写到数据段内,而不能回写到代码段上。
注意:刚才谈到的回写,是指运行时修改,更专业的称谓应该是运行时重定位,与之相对应的还有链接时重定位。
说到这里,需要把编译链接过程再展开一下。我们知道,每个编译单元(通常是一个.c文件,比如前面例子中的test.c)都会经历编译和链接两个阶段。
编译阶段是将.c源代码翻译成汇编指令的中间文件,比如上述的test.c文件,经过编译之后,生成test.o中间文件。print_banner函数的汇编指令如下(使用强调内容objdump -d test.o命令即可输出):
00000000 <print_banner>:
0: 55 push %ebp
1: 89 e5 mov %esp, %ebp
3: 83 ec 08 sub $0x8, %esp
6: c7 04 24 00 00 00 00 movl $0x0, (%esp)
d: e8 fc ff ff ff call e <print_banner+0xe>
12: c9 leave
13: c3 ret是否注意到call指令的操作数是fc ff ff ff,翻译成16进制数是0xfffffffc(x86架构是小端的字节序),看成有符号是-4。这里应该存放printf函数的地址,但由于编译阶段无法知道printf函数的地址,所以预先放一个-4在这里,然后用重定位项来描述:这个地址在链接时要修正,它的修正值是根据printf地址(更确切的叫法应该是符号,链接器眼中只有符号,没有所谓的函数和变量)来修正,它的修正方式按相对引用方式。
这个过程称为链接时重定位,与刚才提到的运行时重定位工作原理完全一样,只是修正时机不同。
链接阶段是将一个或者多个中间文件(.o文件)通过链接器将它们链接成一个可执行文件,链接阶段主要完成以下事情:
- 各个中间文之间的同名section合并
- 对代码段,数据段以及各符号进行地址分配
- 链接时重定位修正
除了重定位过程,其它动作是无法修改中间文件中函数体内指令的,而重定位过程也只能是修改指令中的操作数,换句话说,链接过程无法修改编译过程生成的汇编指令。
那么问题来了:编译阶段怎么知道printf函数是在glibc运行库的,而不是定义在其它.o中
答案往往令人失望:编译器是无法知道的
那么编译器只能老老实实地生成调用printf的汇编指令,printf是在glibc动态库定位,或者是在其它.o定义这两种情况下,它都能工作。如果是在其它.o中定义了printf函数,那在链接阶段,printf地址已经确定,可以直接重定位。如果printf定义在动态库内(链接阶段是可以知道printf在哪定义的,只是如果定义在动态库内不知道它的地址而已),链接阶段无法做重定位。
根据前面讨论,运行时重定位是无法修改代码段的,只能将printf重定位到数据段。那在编译阶段就已生成好的call指令,怎么感知这个已重定位好的数据段内容呢?
答案是:链接器生成一段额外的小代码片段,通过这段代码支获取printf函数地址,并完成对它的调用。
链接器生成额外的伪代码如下:
.text
...
// 调用printf的call指令
call printf_stub
...
printf_stub:
mov rax, [printf函数的储存地址] // 获取printf重定位之后的地址
jmp rax // 跳过去执行printf函数
.data
...
printf函数的储存地址:
这里储存printf函数重定位后的地址链接阶段发现printf定义在动态库时,链接器生成一段小代码print_stub,然后printf_stub地址取代原来的printf。因此转化为链接阶段对printf_stub做链接重定位,而运行时才对printf做运行时重定位。
动态链接姐妹花PLT与GOT
前面由一个简单的例子说明动态链接需要考虑的各种因素,但实际总结起来说两点:
- 需要存放外部函数的数据段
- 获取数据段存放函数地址的一小段额外代码
如果可执行文件中调用多个动态库函数,那每个函数都需要这两样东西,这样每样东西就形成一个表,每个函数使用中的一项。
总不能每次都叫这个表那个表,于是得正名。存放函数地址的数据表,称为全局偏移表(GOT, Global Offset Table),而那个额外代码段表,称为程序链接表(PLT,Procedure Link Table)。它们两姐妹各司其职,联合出手上演这一出运行时重定位好戏。
那么PLT和GOT长得什么样子呢?前面已有一些说明,下面以一个例子和简单的示意图来说明PLT/GOT是如何运行的。
假设最开始的示例代码test.c增加一个write_file函数,在该函数里面调用glibc的write实现写文件操作。根据前面讨论的PLT和GOT原理,test在运行过程中,调用方(如print_banner和write_file)是如何通过PLT和GOT穿针引线之后,最终调用到glibc的printf和write函数的?
我简单画了PLT和GOT雏形图,供各位参考。
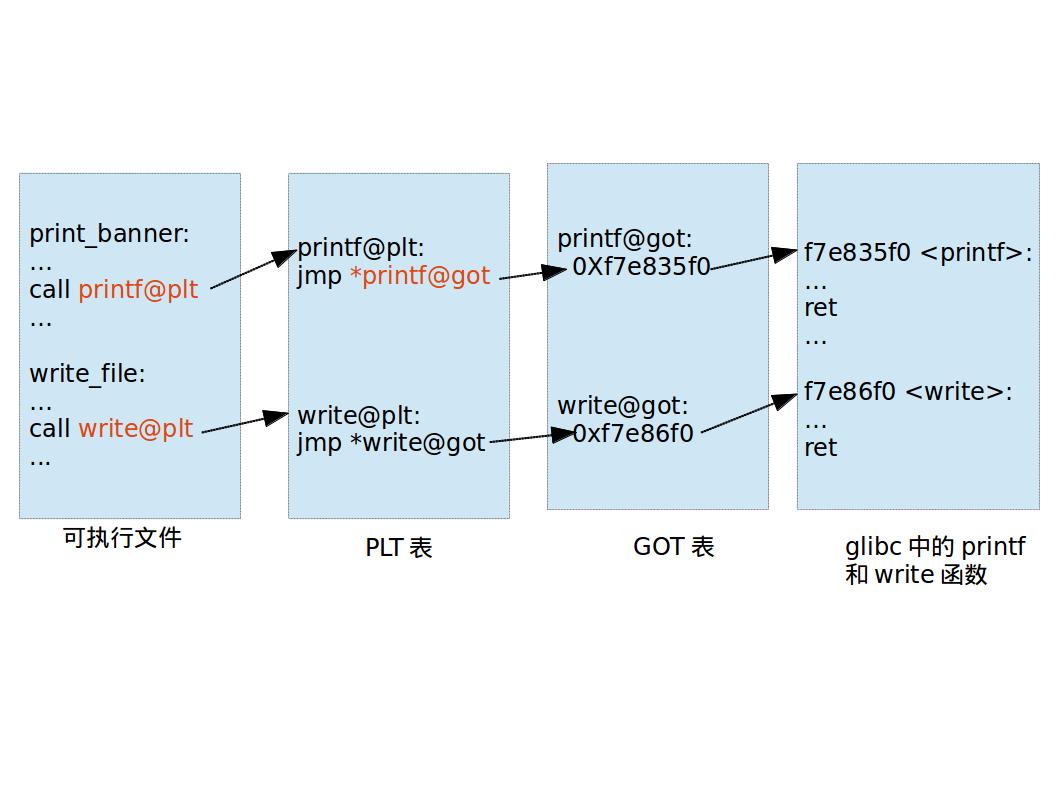
当然这个原理图并不是Linux下的PLT/GOT真实过程,Linux下的PLT/GOT还有更多细节要考虑了。这个图只是将这些躁声全部消除,让大家明确看到PLT/GOT是如何穿针引线的。
ELF格式文件和BIN文件的区别
(以下内容来源于csdn「落叶随枫」)
ELF文件格式是一个开放标准,各种UNIX系统的可执行文件都采用ELF格式,它有三种不同的类型:
可重定位的目标文件(Relocatable,或者Object File)
可执行文件(Executable)
共享库(Shared Object,或者Shared Library)
ELF格式提供了两种不同的视角,链接器把ELF文件看成是Section的集合,而加载器把ELF文件看成是Segment的集合。
有一篇文章介绍elf文件的格式以及加载过程介绍的很详细,可以看一下,地址:http://www.iteye.com/topic/1121480BIN文件是直接的二进制文件,内部没有地址标记。bin文件内部数据按照代码段或者数据段的物理空间地址来排列。一般用编程器烧写时从00开始,而如果下载运行,则下载到编译时的地址即可。
在Linux OS上,为了运行可执行文件,他们是遵循ELF格式的,通常gcc -o test test.c,生成的test文件就是ELF格式的,这样就可以运行了,执行elf文件,则内核会使用加载器来解析elf文件并执行。
在Embedded中,如果上电开始运行,没有OS系统,如果将ELF格式的文件烧写进去,包含一些ELF文件的符号表字符表之类的section,运行碰到这些,就会导致失败,如果用objcopy生成纯粹的二进制文件,去除掉符号表之类的section,只将代码段数据段保留下来,程序就可以一步一步运行。
elf文件里面包含了符号表等。BIN文件是将elf文件中的代码段,数据段,还有一些自定义的段抽取出来做成的一个内存的镜像。 并且elf文件中代码段数据段的位置并不是它实际的物理位置。他实际物理位置是在表中标记出来的。
elf文件的格式以及加载过程介绍
想起来读研的时候做的一个关于程序加载和链接的课程设计,是以Hello World为例说明的,随发出来共享。
**本文的目的:**大家对于Hello World程序应该非常熟悉,随便使用哪一种语言,即使还不熟悉的语言,写出一个Hello World程序应该毫不费力,但是如果让大家详细的说明这个程序加载和链接的过程,以及后续的符号动态解析过程,可能还会有点困难。本文就是以一个最基本的C语言版本Hello World程序为基础,了解Linux下ELF文件的格式,分析并验证ELF文件和加载和动态链接的具有实现。
C代码
/* hello.c */
#include <stdio.h>
int main()
{
printf(“hello world!\n”);
return 0;
}
$ gcc –o hello hello.c 本文的实验平台:
Ubuntu 7.04 Linux kernel 2.6.20 gcc 4.1.2 glibc 2.5 gdb 6.6 objdump/readelf 2.17.50
本文的组织:
第一部分大致描述ELF文件的格式;
第二部分分析ELF文件在内核空间的加载过程;
第三部分分析ELF文件在运行过程中符号的动态解析过程;
(以上各部分都是以Hello World程序为例说明)
第四部分简要总结;
第五部分阐明需要深入了解的东西。
ELF****文件格式
概述
Executable and Linking Format(ELF)文件是x86 Linux系统下的一种常用目标文件(object file)格式,有三种主要类型:
适于连接的可重定位文件(relocatable file),可与其它目标文件一起创建可执行文件和共享目标文件。
适于执行的可执行文件(executable file),用于提供程序的进程映像,加载的内存执行。
共享目标文件(shared object file),连接器可将它与其它可重定位文件和共享目标文件连接成其它的目标文件,动态连接器又可将它与可执行文件和其它共享目标文件结合起来创建一个进程映像。
ELF文件格式比较复杂,本文只是简要介绍它的结构,希望能给想了解ELF文件结构的读者以帮助。具体详尽的资料请参阅专门的ELF文档。
文件格式
为了方便和高效,ELF文件内容有两个平行的视角:一个是程序连接角度,另一个是程序运行角度,如图所示。
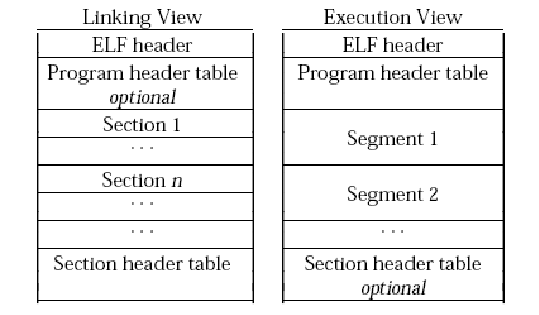
ELF header在文件开始处描述了整个文件的组织,Section提供了目标文件的各项信息(如指令、数据、符号表、重定位信息等),Program header table指出怎样创建进程映像,含有每个program header的入口,section header table包含每一个section的入口,给出名字、大小等信息。
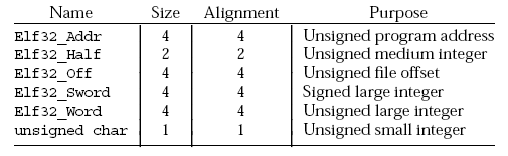
数据表示
ELF数据编码顺序与机器相关,数据类型有六种,见下表:
ELF****文件头
象bmp、exe等文件一样,ELF的文件头包含整个文件的控制结构。它的定义如下:
C代码
190 #define EI_NIDENT 16
191
192 typedef struct elf32_hdr{
193 unsigned char e_ident[EI_NIDENT];
194 Elf32_Half e_type; /* file type */
195 Elf32_Half e_machine; /* architecture */
196 Elf32_Word e_version;
197 Elf32_Addr e_entry; /* entry point */
198 Elf32_Off e_phoff; /* PH table offset */
199 Elf32_Off e_shoff; /* SH table offset */
200 Elf32_Word e_flags;
201 Elf32_Half e_ehsize; /* ELF header size in bytes */
202 Elf32_Half e_phentsize; /* PH size */
203 Elf32_Half e_phnum; /* PH number */
204 Elf32_Half e_shentsize; /* SH size */
205 Elf32_Half e_shnum; /* SH number */
206 Elf32_Half e_shstrndx; /* SH name string table index */
207 } Elf32_Ehdr; 其中E_ident的16个字节标明是个ELF文件(7F+‘E’+‘L’+‘F’)。e_type表示文件类型,2表示可执行文件。e_machine说明机器类别,3表示386机器,8表示MIPS机器。e_entry给出进程开始的虚地址,即系统将控制转移的位置。e_phoff指出program header table的文件偏移,e_phentsize表示一个program header表中的入口的长度(字节数表示),e_phnum给出program header表中的入口数目。类似的,e_shoff,e_shentsize,e_shnum 分别表示section header表的文件偏移,表中每个入口的的字节数和入口数目。e_flags给出与处理器相关的标志,e_ehsize给出ELF文件头的长度(字节数表示)。e_shstrndx表示section名表的位置,指出在section header表中的索引。
Section Header
目标文件的section header table可以定位所有的section,它是一个Elf32_Shdr结构的数组,Section头表的索引是这个数组的下标。有些索引号是保留的,目标文件不能使用这些特殊的索引。
Section包含目标文件除了ELF文件头、程序头表、section头表的所有信息,而且目标文件section满足几个条件:
目标文件中的每个section都只有一个section头项描述,可以存在不指示任何section的section头项。
每个section在文件中占据一块连续的空间。
Section之间不可重叠。
目标文件可以有非活动空间,各种headers和sections没有覆盖目标文件的每一个字节,这些非活动空间是没有定义的。
Section header结构定义如下:
C代码
288 typedef struct {
289 Elf32_Word sh_name; /* name of section, index */
290 Elf32_Word sh_type;
291 Elf32_Word sh_flags;
292 Elf32_Addr sh_addr; /* memory address, if any */
293 Elf32_Off sh_offset;
294 Elf32_Word sh_size; /* section size in file */
295 Elf32_Word sh_link;
296 Elf32_Word sh_info;
297 Elf32_Word sh_addralign;
298 Elf32_Word sh_entsize; /* fixed entry size, if have */
299 } Elf32_Shdr; 其中sh_name指出section的名字,它的值是后面将会讲到的section header string table中的索引,指出一个以null结尾的字符串。sh_type是类别,sh_flags指示该section在进程执行时的特性。sh_addr指出若此section在进程的内存映像中出现,则给出开始的虚地址。sh_offset给出此section在文件中的偏移。其它字段的意义不太常用,在此不细述。
文件的section含有程序和控制信息,系统使用一些特定的section,并有其固定的类型和属性(由sh_type和sh_info指出)。下面介绍几个常用到的section:“.bss”段含有占据程序内存映像的未初始化数据,当程序开始运行时系统对这段数据初始为零,但这个section并不占文件空间。“.data.”和“.data1”段包含占据内存映像的初始化数据。“.rodata”和“.rodata1”段含程序映像中的只读数据。“.shstrtab”段含有每个section的名字,由section入口结构中的sh_name索引。“.strtab”段含有表示符号表(symbol table)名字的字符串。“.symtab”段含有文件的符号表,在后文专门介绍。“.text”段包含程序的可执行指令。
当然一个实际的ELF文件中,会包含很多的section,如.got,.plt等等,我们这里就不一一细述了,需要时再详细的说明。
Program Header
目标文件或者共享文件的program header table描述了系统执行一个程序所需要的段或者其它信息。目标文件的一个段(segment)包含一个或者多个section。Program header只对可执行文件和共享目标文件有意义,对于程序的链接没有任何意义。结构定义如下:
C代码
232 typedef struct elf32_phdr{
233 Elf32_Word p_type;
234 Elf32_Off p_offset;
235 Elf32_Addr p_vaddr; /* virtual address */
236 Elf32_Addr p_paddr; /* ignore */
237 Elf32_Word p_filesz; /* segment size in file */
238 Elf32_Word p_memsz; /* size in memory */
239 Elf32_Word p_flags;
240 Elf32_Word p_align;
241 } Elf32_Phdr; 其中p_type描述段的类型;p_offset给出该段相对于文件开关的偏移量;p_vaddr给出该段所在的虚拟地址;p_paddr给出该段的物理地址,在Linux x86内核中,这项并没有被使用;p_filesz给出该段的大小,在字节为单元,可能为0;p_memsz给出该段在内存中所占的大小,可能为0;p_filesze与p_memsz的值可能会不相等。
Symbol Table
目标文件的符号表包含定位或重定位程序符号定义和引用时所需要的信息。符号表入口结构定义如下:
C代码
171 typedef struct elf32_sym{
172 Elf32_Word st_name;
173 Elf32_Addr st_value;
174 Elf32_Word st_size;
175 unsigned char st_info;
176 unsigned char st_other;
177 Elf32_Half st_shndx;
178 } Elf32_Sym; 其中st_name包含指向符号表字符串表(strtab)中的索引,从而可以获得符号名。st_value指出符号的值,可能是一个绝对值、地址等。st_size指出符号相关的内存大小,比如一个数据结构包含的字节数等。st_info规定了符号的类型和绑定属性,指出这个符号是一个数据名、函数名、section名还是源文件名;并且指出该符号的绑定属性是local、global还是weak。
Section和Segment的区别和联系
可执行文件中,一个program header描述的内容称为一个段(segment)。Segment包含一个或者多个section,我们以Hello World程序为例,看一下section与segment的映射关系:
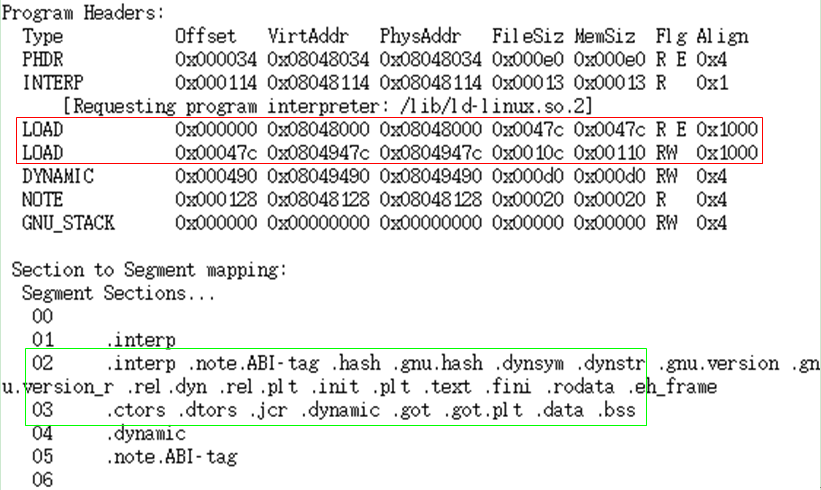
如上图红色区域所示,就是我们经常提到的文本段和数据段,由图中绿色部分的映射关系可知,文本段并不仅仅包含.text节,数据段也不仅仅包含.data节,而是都包含了多个section。
ELF文件的加载过程
加载和动态链接的简要介绍
从编译/链接和运行的角度看,应用程序和库程序的连接有两种方式。一种是固定的、静态的连接,就是把需要用到的库函数的目标代码(二进制)代码从程序库中抽取出来,链接进应用软件的目标映像中;另一种是动态链接,是指库函数的代码并不进入应用软件的目标映像,应用软件在编译/链接阶段并不完成跟库函数的链接,而是把函数库的映像也交给用户,到启动应用软件目标映像运行时才把程序库的映像也装入用户空间(并加以定位),再完成应用软件与库函数的连接。
这样,就有了两种不同的ELF格式映像。一种是静态链接的,在装入/启动其运行时无需装入函数库映像、也无需进行动态连接。另一种是动态连接,需要在装入/启动其运行时同时装入函数库映像并进行动态链接。Linux内核既支持静态链接的ELF映像,也支持动态链接的ELF映像,而且装入/启动ELF映像必需由内核完成,而动态连接的实现则既可以在内核中完成,也可在用户空间完成。因此,GNU把对于动态链接ELF映像的支持作了分工:把ELF映像的装入/启动入在Linux内核中;而把动态链接的实现放在用户空间(glibc),并为此提供一个称为“解释器”(ld-linux.so.2)的工具软件,而解释器的装入/启动也由内核负责,这在后面我们分析ELF文件的加载时就可以看到。
这部分主要说明ELF文件在内核空间的加载过程,下一部分对用户空间符号的动态解析过程进行说明。
Linux可执行文件类型的注册机制
在说明ELF文件的加载过程以前,我们先回答一个问题,就是:为什么Linux可以运行ELF文件?
回答:内核对所支持的每种可执行的程序类型都有个struct linux_binfmt的数据结构,定义如下:
C代码
53 /*
54 * This structure defines the functions that are used to load the binary formats that
55 * linux accepts.
56 */
57 struct linux_binfmt {
58 struct linux_binfmt * next;
59 struct module module;
60 int (load_binary)(struct linux_binprm *, struct pt_regs * regs);
61 int (*load_shlib)(struct file )
62 int (core_dump)(long signr, struct pt_regs * regs, struct file * file);
63 unsigned long min_coredump; /* minimal dump size */
64 int hasvdso;
65 }; 其中的load_binary函数指针指向的就是一个可执行程序的处理函数。而我们研究的ELF文件格式的定义如下:
C代码
74 static struct linux_binfmt elf_format = {
75 .module = THIS_MODULE,
76 .load_binary = load_elf_binary,
77 .load_shlib = load_elf_library,
78 .core_dump = elf_core_dump,
79 .min_coredump = ELF_EXEC_PAGESIZE,
80 .hasvdso = 1
81 }; 要支持ELF文件的运行,则必须向内核登记这个数据结构,加入到内核支持的可执行程序的队列中。内核提供两个函数来完成这个功能,一个注册,一个注销,即:
C代码
72 int register_binfmt(struct linux_binfmt * fmt)
96 int unregister_binfmt(struct linux_binfmt * fmt) 当需要运行一个程序时,则扫描这个队列,让各个数据结构所提供的处理程序,ELF中即为load_elf_binary,逐一前来认领,如果某个格式的处理程序发现相符后,便执行该格式映像的装入和启动。
内核空间的加载过程
内核中实际执行execv()或execve()系统调用的程序是do_execve(),这个函数先打开目标映像文件,并从目标文件的头部(第一个字节开始)读入若干(当前Linux内核中是128)字节(实际上就是填充ELF文件头,下面的分析可以看到),然后调用另一个函数search_binary_handler(),在此函数里面,它会搜索我们上面提到的Linux支持的可执行文件类型队列,让各种可执行程序的处理程序前来认领和处理。如果类型匹配,则调用load_binary函数指针所指向的处理函数来处理目标映像文件。在ELF文件格式中,处理函数是load_elf_binary函数,下面主要就是分析load_elf_binary函数的执行过程(说明:因为内核中实际的加载需要涉及到很多东西,这里只关注跟ELF文件的处理相关的代码):
C代码
550 struct {
551 struct elfhdr elf_ex;
552 struct elfhdr interp_elf_ex;
553 struct exec interp_ex;
554 } loc;
556 loc = kmalloc(sizeof(loc), GFP_KERNEL);
562 /* Get the exec-header */
563 loc->elf_ex = *((struct elfhdr *)bprm->buf);
……
566 /* First of all, some simple consistency checks */
567 if (memcmp(loc->elf_ex.e_ident, ELFMAG, SELFMAG) != 0)
568 goto out;
570 if (loc->elf_ex.e_type != ET_EXEC && loc->elf_ex.e_type != ET_DYN)
571 goto out; 在load_elf_binary之前,内核已经使用映像文件的前128个字节对bprm->buf进行了填充,563行就是使用这此信息填充映像的文件头(具体数据结构定义见第一部分,ELF文件头节),然后567行就是比较文件头的前四个字节,查看是否是ELF文件类型定义的“\177ELF”。除这4个字符以外,还要看映像的类型是否ET_EXEC和ET_DYN之一;前者表示可执行映像,后者表示共享库。
C代码
577 /* Now read in all of the header information */
580 if (loc->elf_ex.e_phnum < 1 ||
581 loc->elf_ex.e_phnum > 65536U / sizeof(struct elf_phdr))
582 goto out;
583 size = loc->elf_ex.e_phnum * sizeof(struct elf_phdr);
……
585 elf_phdata = kmalloc(size, GFP_KERNEL);
……
589 retval = kernel_read(bprm->file, loc->elf_ex.e_phoff,
590 (char *)elf_phdata, size); 这块就是通过kernel_read读入整个program header table。从代码中可以看到,一个可执行程序必须至少有一个段(segment),而所有段的大小之和不能超过64K。
C代码
614 elf_ppnt = elf_phdata;
……
623 for (i = 0; i < loc->elf_ex.e_phnum; i++) {
624 if (elf_ppnt->p_type == PT_INTERP) {
……
635 elf_interpreter = kmalloc(elf_ppnt->p_filesz, GFP_KERNEL);
……
640 retval = kernel_read(bprm->file, elf_ppnt->p_offset,
641 elf_interpreter,
642 elf_ppnt->p_filesz);
……
682 interpreter = open_exec(elf_interpreter);
……
695 retval = kernel_read(interpreter, 0, bprm->buf,
696 BINPRM_BUF_SIZE);
……
703 /* Get the exec headers */
……
705 loc->interp_elf_ex = *((struct elfhdr *)bprm->buf);
706 break;
707 }
708 elf_ppnt++;
709 } 这个for循环的目的在于寻找和处理目标映像的“解释器”段。“解释器”段的类型为PT_INTERP,找到后就根据其位置的p_offset和大小p_filesz把整个“解释器”段的内容读入缓冲区(640640)。事个“解释器”段实际上只是一个字符串,即解释器的文件名,如“/lib/ld-linux.so.2”。有了解释器的文件名以后,就通过open_exec()打开这个文件,再通过kernel_read()读入其开关128个字节(695696),即解释器映像的头部。我们以Hello World程序为例,看一下这段中具体的内容:
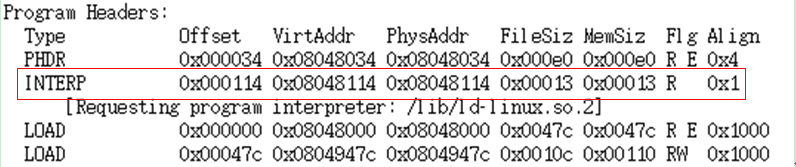
其实从readelf程序的输出中,我们就可以看到需要解释器/lib/ld-linux.so.2,为了进一步的验证,我们用hd命令以16进制格式查看下类型为INTERP的段所在位置的内容,在上面的各个域可以看到,它位于偏移量为0x000114的位置,文件内占19个字节:

从上面红色部分可以看到,这个段中实际保存的就是“/lib/ld-linux.so.2”这个字符串。
C代码
814 for(i = 0, elf_ppnt = elf_phdata;
815 i < loc->elf_ex.e_phnum; i++, elf_ppnt++) {
……
819 if (elf_ppnt->p_type != PT_LOAD)
820 continue;
……
870 error = elf_map(bprm->file, load_bias + vaddr, elf_ppnt,
871 elf_prot, elf_flags);
……
920 } 这段代码从目标映像的程序头中搜索类型为PT_LOAD的段(Segment)。在二进制映像中,只有类型为PT_LOAD的段才是需要装入的。当然在装入之前,需要确定装入的地址,只要考虑的就是页面对齐,还有该段的p_vaddr域的值(上面省略这部分内容)。确定了装入地址后,就通过elf_map()建立用户空间虚拟地址空间与目标映像文件中某个连续区间之间的映射,其返回值就是实际映射的起始地址。
C代码
946 if (elf_interpreter) {
……
951 elf_entry = load_elf_interp(&loc->interp_elf_ex,
952 interpreter,
953 &interp_load_addr);
……
965 } else {
966 elf_entry = loc->elf_ex.e_entry;
……
972 }这段程序的逻辑非常简单:如果需要装入解释器,就通过load_elf_interp装入其映像(951~953),并把将来进入用户空间的入口地址设置成load_elf_interp()的返回值,即解释器映像的入口地址。而若不装入解释器,那么这个入口地址就是目标映像本身的入口地址。
C代码
991 create_elf_tables(bprm, &loc->elf_ex,
992 (interpreter_type == INTERPRETER_AOUT),
993 load_addr, interp_load_addr);
……
1028 start_thread(regs, elf_entry, bprm->p); 在完成装入,启动用户空间的映像运行之前,还需要为目标映像和解释器准备好一些有关的信息,这些信息包括常规的argc、envc等等,还有一些“辅助向量(Auxiliary Vector)”。这些信息需要复制到用户空间,使它们在CPU进入解释器或目标映像的程序入口时出现在用户空间堆栈上。这里的create_elf_tables()就起着这个作用。
最后,start_thread()这个宏操作会将eip和esp改成新的地址,就使得CPU在返回用户空间时就进入新的程序入口。如果存在解释器映像,那么这就是解释器映像的程序入口,否则就是目标映像的程序入口。那么什么情况下有解释器映像存在,什么情况下没有呢?如果目标映像与各种库的链接是静态链接,因而无需依靠共享库、即动态链接库,那就不需要解释器映像;否则就一定要有解释器映像存在。
以我们的Hello World为例,gcc在编译时,除非显示的使用static标签,否则所有程序的链接都是动态链接的,也就是说需要解释器。由此可见,我们的Hello World程序在被内核加载到内存,内核跳到用户空间后并不是执行Hello World的,而是先把控制权交到用户空间的解释器,由解释器加载运行用户程序所需要的动态库(Hello World需要libc),然后控制权才会转移到用户程序。
ELF文件中符号的动态解析过程
上面一节提到,控制权是先交到解释器,由解释器加载动态库,然后控制权才会到用户程序。因为时间原因,动态库的具体加载过程,并没有进行深入分析。大致的过程就是将每一个依赖的动态库都加载到内存,并形成一个链表,后面的符号解析过程主要就是在这个链表中搜索符号的定义。
我们后面主要就是以Hello World为例,分析程序是如何调用printf的:
查看一下gcc编译生成的Hello World程序的汇编代码(main函数部分):
C代码
08048374 <main>:
8048374: 8d 4c 24 04 lea 0x4(%esp),%ecx
……
8048385: c7 04 24 6c 84 04 08 movl $0x804846c,(%esp)
804838c: e8 2b ff ff ff call 80482bc <puts@plt>
8048391: b8 00 00 00 00 mov $0x0,%eax 从上面的代码可以看出,经过编译后,printf函数的调用已经换成了puts函数(原因读者可以想一下)。其中的call指令就是调用puts函数。但从上面的代码可以看出,它调用的是puts@plt这个标号,它代表什么意思呢?在进一步说明符号的动态解析过程以前,需要先了解两个概念,一个是global offset table,一个是procedure linkage table。
Global Offset Table(GOT)
在位置无关代码中,一般不能包含绝对虚拟地址(如共享库)。当在程序中引用某个共享库中的符号时,编译链接阶段并不知道这个符号的具体位置,只有等到动态链接器将所需要的共享库加载时进内存后,也就是在运行阶段,符号的地址才会最终确定。因此,需要有一个数据结构来保存符号的绝对地址,这就是GOT表的作用,GOT表中每项保存程序中引用其它符号的绝对地址。这样,程序就可以通过引用GOT表来获得某个符号的地址。
在x86结构中,GOT表的前三项保留,用于保存特殊的数据结构地址,其它的各项保存符号的绝对地址。对于符号的动态解析过程,我们只需要了解的就是第二项和第三项,即GOT[1]和GOT[2]:GOT[1]保存的是一个地址,指向已经加载的共享库的链表地址(前面提到加载的共享库会形成一个链表);GOT[2]保存的是一个函数的地址,定义如下:GOT[2] = &_dl_runtime_resolve,这个函数的主要作用就是找到某个符号的地址,并把它写到与此符号相关的GOT项中,然后将控制转移到目标函数,后面我们会详细分析。
Procedure Linkage Table(PLT
过程链接表(PLT)的作用就是将位置无关的函数调用转移到绝对地址。在编译链接时,链接器并不能控制执行从一个可执行文件或者共享文件中转移到另一个中(如前所说,这时候函数的地址还不能确定),因此,链接器将控制转移到PLT中的某一项。而PLT通过引用GOT表中的函数的绝对地址,来把控制转移到实际的函数。
在实际的可执行程序或者共享目标文件中,GOT表在名称为.got.plt的section中,PLT表在名称为.plt的section中。
大致的了解了GOT和PLT的内容后,我们查看一下puts@plt中到底是什么内容:
Disassembly of section .plt:
0804828c <__gmon_start__@plt-0x10>:
804828c: ff 35 68 95 04 08 pushl 0x8049568
8048292: ff 25 6c 95 04 08 jmp *0x804956c
8048298: 00 00
......
0804829c <__gmon_start__@plt>:
804829c: ff 25 70 95 04 08 jmp *0x8049570
80482a2: 68 00 00 00 00 push $0x0
80482a7: e9 e0 ff ff ff jmp 804828c <_init+0x18>
080482ac <__libc_start_main@plt>:
80482ac: ff 25 74 95 04 08 jmp *0x8049574
80482b2: 68 08 00 00 00 push $0x8
80482b7: e9 d0 ff ff ff jmp 804828c <_init+0x18>
080482bc <puts@plt>:
80482bc: ff 25 78 95 04 08 jmp *0x8049578
80482c2: 68 10 00 00 00 push $0x10
80482c7: e9 c0 ff ff ff jmp 804828c <_init+0x18> 可以看到puts@plt包含三条指令,程序中所有对有puts函数的调用都要先来到这里(Hello World里只有一次)。可以看出,除PLT0以外(就是__gmon_start__@plt-0x10所标记的内容),其它的所有PLT项的形式都是一样的,而且最后的jmp指令都是0x804828c,即PLT0为目标的。所不同的只是第一条jmp指令的目标和push指令中的数据。PLT0则与之不同,但是包括PLT0在内的每个表项都占16个字节,所以整个PLT就像个数组(实际是代码段)。另外,每个PLT表项中的第一条jmp指令是间接寻址的。
发表回复